-
 Blog
Blog
-
What can Clone Detection across System Boundaries ...

Teams, not individuals, build most software systems. The organization of these teams thus strongly impacts the software they build.
This is old news. For example, Conway’s law illustrates that the architectural decomposition of a system into components happens along communication structures [1]. Naggapan’s study on bug data from Windows Vista shows that organizational structure is a significant predictor for fault proneness [2].
These empirical results resonate with my own experience. Often, the problems our static code analyses reveal in a code base are symptoms of underlying organizational problems. The larger the organizational problems, the bigger their impact on code quality.
Unfortunately, on this level of abstraction, this insight is pretty useless, since it is too abstract to be operationalized in a project context. To make it applicable, I want to boil it down to a single aspect in this article: reuse. From my experience, it is one of the code characteristics that reveals most about collaboration between teams.
Structured and Ad-hoc reuse
I differentiate between two forms of reuse: in structure reuse, each reused artifact (e.g. library, class, method, …) gets maintained in a single location. Changes to this central artifact thus affect all locations it gets used in. In Ad hoc reuse, each reused artifact gets copied into its new location. Changes are performed to the copies independently. If and how they are propagated between copies varies.
Both forms of reuse have pros and cons. The main advantages of structured reuse is that changes only need to be performed once, reducing maintenance effort and simplifying bug fixing in reused artifacts. Its main disadvantage is that it requires coordination. If an artifact is heavily reused, substantial changes may cause problems for its users and must be coordinated. Ad hoc reuse simply inverts those attributes: changes can be made independent of each other. While this is helpful for e.g. experimentation, it unfortunately makes bug fixes hard.
Ad hoc reuse is often applied in practice. My observation is, however, that it is often chosen to work around coordination problems between different teams, not because it is the best solution for the given reuse situation.
Clone detection can reliably detect ad hoc reuse. We can thus use it as a team/organization problem detector.
Clone Detection in a nutshell
Clone detection discovers similar areas of code. Detection algorithms are smart enough to compensate small changes, such as renamed variables or changes to source code comments. Clone detection is fast enough to analyze systems with several million lines of code in less than an hour. See [3] for more information on clone detection.
In most cases, clone detection gets used to discover and help manage code duplicates inside a single system. To inspect clone detection results on the level of a whole system, we use cushion treemaps. They are best explained in following the steps of the layout algorithm:
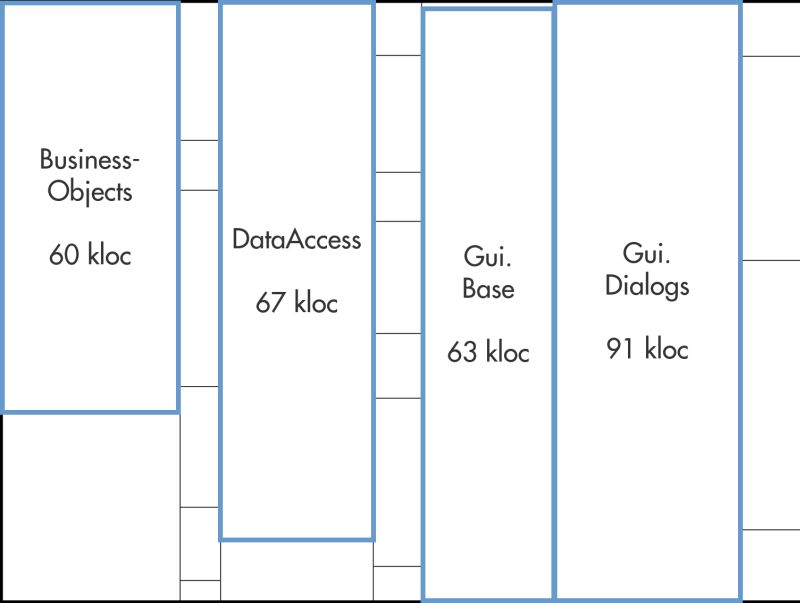
This treemap depicts each component of the system under analysis as a rectangle. The surface area of the rectangle corresponds to the size of its component in lines of code; the more lines, the larger the rectangle.
I have highlighted four components in blue. All other rectangles, however, also represent components.
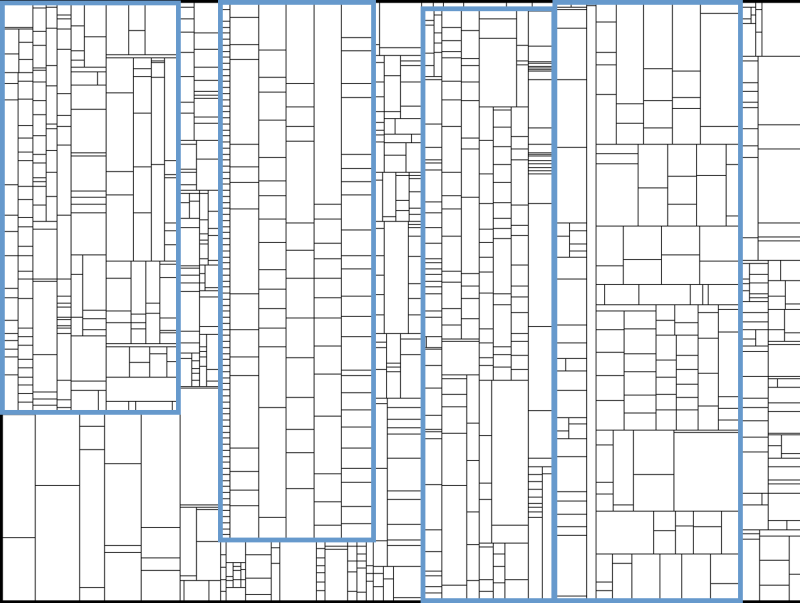
In the next step, subcomponents are layouted. More specifically, a rectangle for each class that is part of a component gets drawn. Again, the size corresponds to the lines of code. Positioning mirrors location in the namespace: if two classes share the same namespace, they are drawn close to each other.
Unfortunately, adding classes threatens to blur the component structure of the system. I have left the four blue rectangles in place, to show that the components are still in the same position in the treemap. However, without the blue rectangles, they would be hard to spot. To preserve structural information, cushions are used to depict hierarchy.

In this step, the layout algorithm renders each rectangle as a cushion in such a way, that namespace hierarchy is still visible. Through the shading of each rectangle, the cushions depict which rectangles together form a larger part of the system (e.g. directory, package, namespace or such).
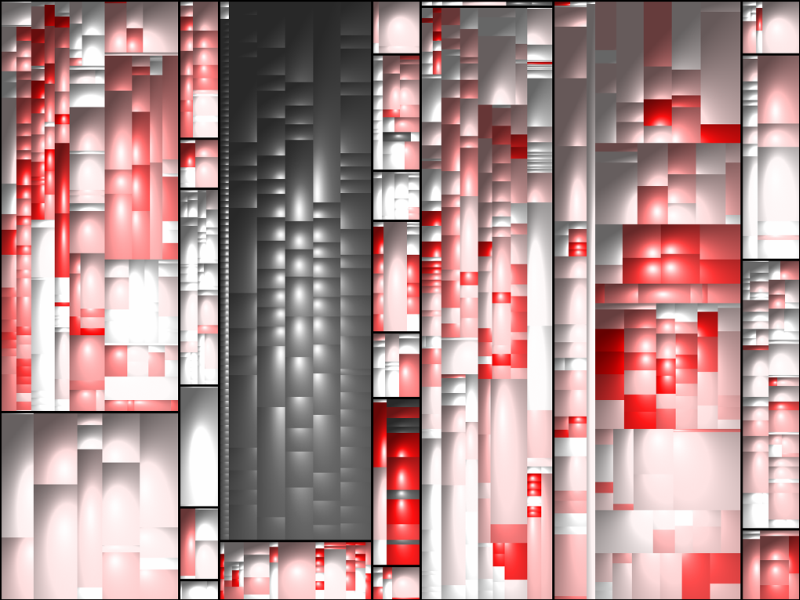
In the last step, we use color to denote the amount of cloning we detected in the system. Dark grey code is generated and thus excluded from detection. All other code gets colored on a gradient from white to red. White == 0% cloned, Dark red == 100% cloned.
This way, the treemap shows us which areas of the system contain how many clones.
Cross-project-clone-detection simply performs a clone detection across the code base of several projects and considers only those clones that span more than one project. Its results can be visualized similarly in a treemap. In the remainder of the post, I use apply it to different project settings.
Ad hoc Reuse across Applications in a Single Company
In the first case, I have used cross-project clone detection on the applications maintained by one single company. Each of the nine applications is a business information system, all are written in the same programming language. They are maintained by different teams. In some areas, the applications interact with each other (e.g. by exchanging data).
Clone detection revealed the following result. In this treemap only those clones are shown that contain copies that span at least two different applications.

We see that several large areas are cloned. Closer inspection revealed that entire components (both of custom UI widgets used by different applications, and of business objects for data shared across applications) have been copied.
Interviews with the developers revealed that, at least in some cases, the components had originally been maintained in a central location. However, the organization failed to create a structured process to manage change to these components. In part, because at that time, the development teams belonged to different companies working under different contracts.
In consequence, the projects duplicated the code. However, inspection of the differences between the clones revealed that many bug fixes had been done inconsistently, or with duplicate debugging and bug-fixing effort across teams.
In the last years, the development teams changed. They now belong to a single company. Their organizational structure has thus changed. It thus makes sense to reevaluate the reuse decisions.
Ad Hoc Reuse in a Product Family
The second example shows ad hoc reuse between the 14 products of a product family.

In this case, the development team simply copied the product for each new customer and modified it according to the customer’s needs, to allow customer teams to work independent of each other. In this case, duplication between the products was thus no surprise but expected.

This treemap shows clones that span at least 5 products in the family. What came as a surprise, however, was how much cloning spanned 10 or more family members:

The analysis revealed that many parts remained entirely unchanged across most or all products. These parts are candidates for structured reuse, to simplify bug fixes to them in the future.
Ad hoc Reuse in a Product Line
The third example shows products from a product line that employs structured reuse: It is built on a foundation of components that encapsulate reusable functionality. The basic idea of the product line designer was thus to not require duplication of code.

Clone detection across products, however, revealed substantial amounts of cloning.

Inspection of the clones, and interviews with the developer teams, revealed that in some cases, developers had changed between product teams and had taken functionality with them. Since it was missing in the reusable components and they had to keep project deadlines, they simply duplicated it.
In this case, this duplication came as a surprise to the team that developed the reusable components. They had not been aware that such functionality was required by multiple teams. As a consequence of this analysis, this functionality was moved into the core components.
Reuse Rationale Changes over Time
The central lesson I took away from these analyses is that the rationale that influenced a certain reuse decision when it was made can change as a project evolves:
-
In the application portfolio example, the team structure changed, removing the problem that caused cloning in the first place.
-
In the product family example, teams were uncertain which functionality was generic and which customer-specific. 14 products later, they had a much clearer picture on what to reuse in a structured manner.
-
In the product line case, the product team’s main focus was to get the product done on time, driving them to copy existing functionality from a different product. The component team’s focus, however, is much more long term, since they have to maintain their product line. It is in their interest to increase the level of structure reuse.
Cross-project clone detection allows us to spot areas in which ad hoc reuse has been performed. It allows us to question if rationale has changed sufficiently to warrant a more structure reuse style.
What is more, even if we do not plan to move from ad hoc to structured reuse, being aware of duplication allows us to alleviate its symptoms by preventing inconsistency bugs.
If you want to experiment with cross-project clone detection, simply drop me an email or write a comment. I am happy to provide you with an analysis configuration for your context. We support over 20 programming languages, so I am positive that yours is among them!
References
[1] Definition of Conway’s Law at Wikipedia
[3] Further links on clone detection:
