-
 Blog
Blog
-
Does Convergent Evolution of Code Produce Code ...

We have had countless discussions about code clones with the teams responsible for their maintenance. These teams generally accept that some of the clones in their software are the product of copy & paste. In many cases this is obvious, since the clones share some quirks that can only be plausibly explained by copy & paste (e.g. identical typos in comments).
One hypothesis that comes up time and again, however, is that some or many of the clones were not created by copy & paste, but instead were written independently and then evolved into the same form.
Convergent Evolution
This hypothesis reminds me of convergent evolution, where environmental factors drive independent evolution of similar traits in species whose ancestors do not show those traits. For example, both pill bugs and pill millipede have evolved similar defenses, and consequently look similar, but belong to different branches of evolution. Convergent evolution is rife in nature, as hundreds of examples on its Wikipedia list impressively show.

For clone management, convergent evolution as a reason for clones would have important implications. Instead of reducing copy & paste to situations in which it is unavoidable, we would have to be constantly vigilant to spot those moments of code evolution, where convergence takes place.
But how likely is convergent evolution for code?
To study this, we need a collection of code fragments that implement similar functionality, but have been created independently (and not through copy & paste). We can then search these code fragments for clones, to determine the likelihood of convergent evolution as a source of clones in practice.
Case Study
To produce such a body of programs for analysis, we asked about 400 computer science students at Technical University of Munich to implement a single specification. (The task was to split a list of email adresses, that gets passed in as a string, and validate them.). To rule out misunderstandings, the students were handed a suite of unit tests that the implementation needed to satisfy.
If students struggle with the task, they might be tempted to copy & paste a solution from others, thereby undermining the study. To mitigate this threat, each implementation was done by teams of two, under supervision of practice group tutors and participation was voluntary. Importantly, success or failure had no influence on student marks.
As a result, we received 109 programs that compiled and successfully passed the unit test suite. All 109 code files thus, w.r.t. the unit test suite and the specification, have similar semantics.
We then ran clone detectors (both ours and those of other groups) on the results. We found very few clones. More specifically, we found less than 1% of the files to be complete clones of at least one other file. We also found less than 10% of the files to share any, even very short, code segments similar enough to be detected as clones.
The reason for this is the very strong variety among solutions. The shortest valid solution had 8 statements, the longest more than 100:
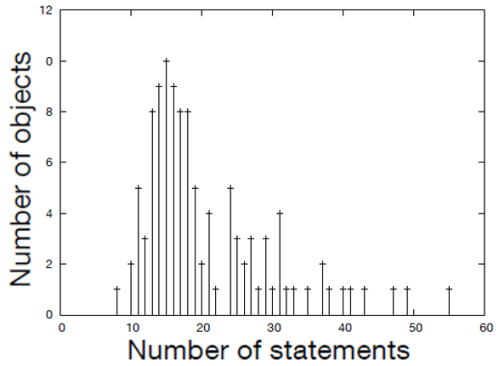
Code complexity differs strongly, too:
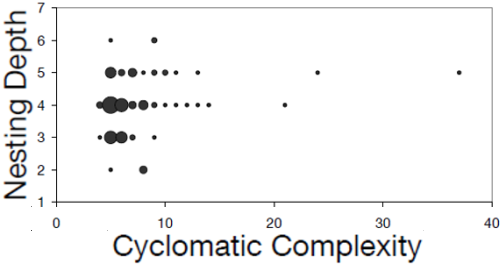
The reasons for these differences are many. One, for example, is choice of different libraries or algorithms. To illustrate this, below are five different solutions to split a string at a separator that gets passed in as a parameter that were used by the students.


Such a study cannot rule out the existence of independently evolved code duplicates in general. It does show, however, that they are extremely unlikely. I am convinced, that the vast majority of the clones I have seen in practice, if not all of them, are not a product of convergent evolution.
A detailed description of the study, including threats to validity, literature research and a more in-depth treatment of the details has been published as a research paper.
What is your experience? Have you seen independently developed code that looks syntactically similar, or are all the clones you have detected a product of copy & paste?
