-
 Blog
Blog
-
Cloned Blocks and Software Anomalies in a Big ...

Code quality audits aim to assess the quality of a system’s source code and identify weak points in it. Two areas of the quality audits that have been discussed in the previous posts by my colleagues are the redundancy caused by copy/paste and the anomalies that go undetected unless static analysis tools like FindBugs are used periodically to check the source code for defects. In the following, I will outline a small experiment meant to see whether the findings of the static analysis tool FindBugs reside in code blocks that have been copied over in other parts of a system’s source code. To illustrate this experiment, I will use a »Big Data« open-source project, namely Apache Hadoop. It is worth mentioning that, related to its code quality, Apache Hadoop was in the spotlight of the 2014 Report on open-source software quality from our colleagues at Coverity.
Static analysis of Apache Hadoop source code
The starting point was the latest stable release of Apache Hadoop 2.6.0. I have configured the static analysis tool Teamscale to take a snapshot of the application code of Hadoop, totaling 769 kLOC spread over 3,933 Java files. The various analyses that Teamscale performs kept my laptop busy for approximately half an hour (my laptop is powered by an Intel i7 processor with 4 cores running at 3,300 MHz).
For clone detection, Teamscale lists a number of 3,721 cloned blocks and computes a percentage of 8.5% clone coverage (see here for a description of the clone coverage metric). Compared to other open-source projects I analyzed with Teamscale, the clone coverage of 8.5% is relatively low. However, from the point of view of a person analyzing a big software project, manually inspecting thousands of cloned blocks to decide which of them are worth refactoring to eliminate the duplication requires a significant amount of time.
For anomaly detection, Teamscale has its own analysis engine and also runs two external analysis tools, FindBugs and PMD. Part of Teamscale’s results are 477 warnings from FindBugs. Apache Hadoop is a software with a low number of defects: the ratio of FindBugs warnings per 1,000 lines of code is small compared to other open-source projects. As an example of the low number of defects, the 477 warnings include only one »NP_NULL_ON_SOME_PATH« warning and only eight »NP_NULL_ON_SOME_PATH_EXCEPTION« warnings, i.e., possible null-pointer dereferences on normal and exception paths. Despite the low density of FindBugs warnings per 1,000 lines of code, still, for a large project like Hadoop, manually inspecting 477 warnings to decide which of them are worth fixing requires a significant amount of time.
Clones of blocks containing FindBugs warnings
In this section, we will not look at all the clone and anomaly findings, rather we will focus only on those anomalies occurring in code blocks that are cloned somewhere else in the Hadoop source code. Thus, I obtained a (short) list of six findings, numbered below R1 to R6.
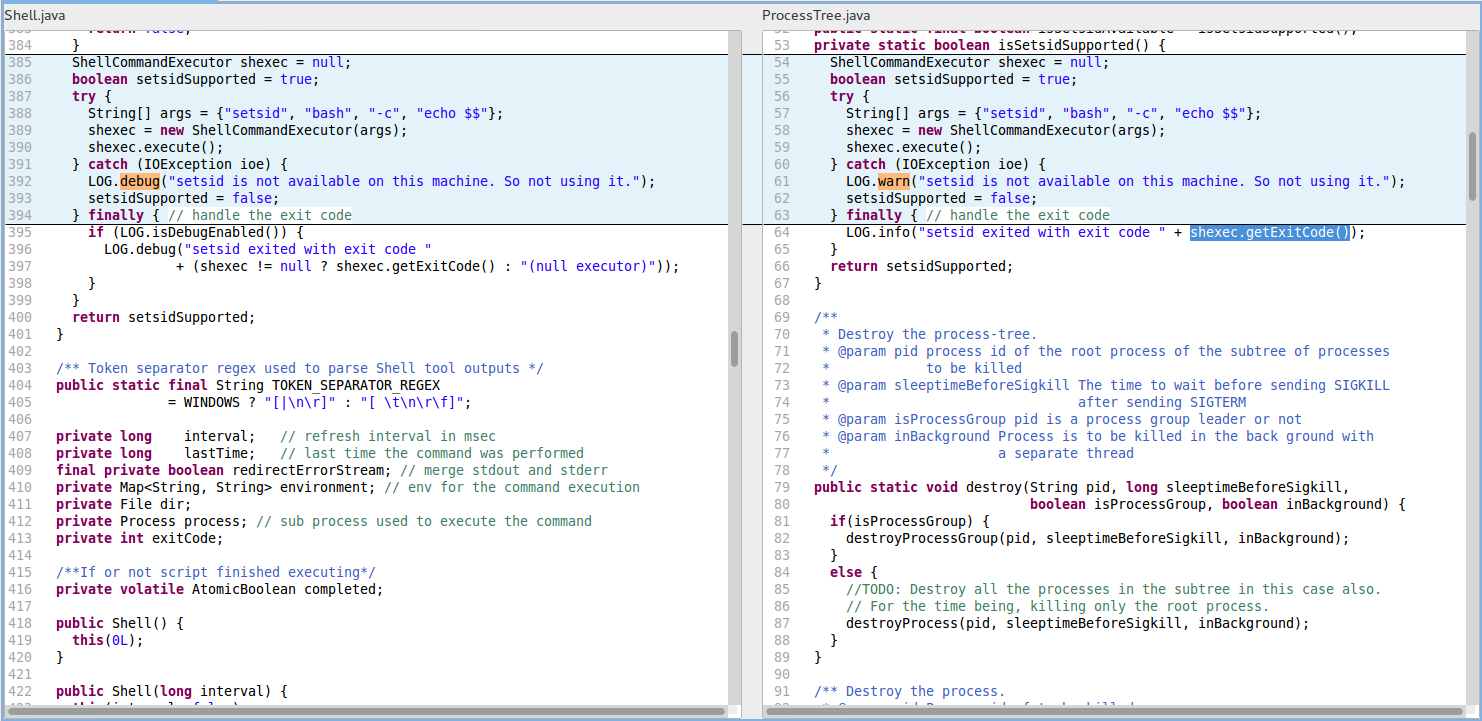
R1. NP_NULL_ON_SOME_PATH_EXCEPTION (Possible null-pointer dereference in method on exception path) in the file hadoop-mapreduce-project/../ProcessTree.java at line 64. (See the right-hand side of the figure below for the code block R1-RightPane.)
A code block similar to R1-RightPane, judged to be a clone by Teamscale, occurs in the file Shell.java (see the left-hand side of the figure below for the code block R1-LeftPane). The block R1-LeftPane, shown on a blue background on the left-hand side of the figure, shows a similarity to R1-RightPane that could be attributed to copy-paste. What is important is that the NullPointerException that would be triggered in the block R1-RightPane at line 64 cannot occur at line 397 of R1-LeftPane where the problem was fixed. However, without information on clones, the developer that fixed the problem in R1-LeftPane failed to address the null-pointer dereference that occurs in R1-RightPane.
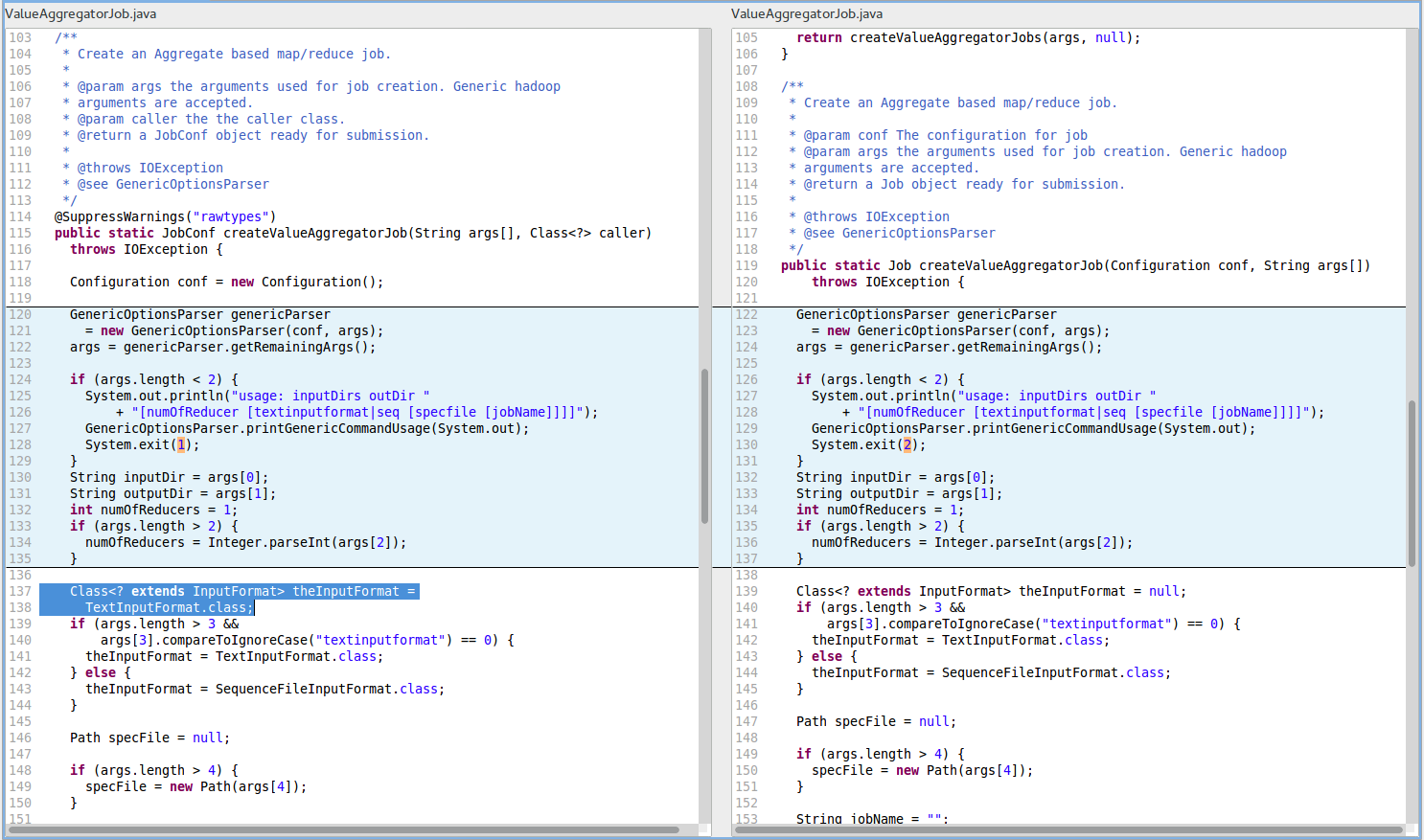
R2. DLS_DEAD_STORE_OF_CLASS_LITERAL (Dead store of class literal) in the file hadoop-mapreduce-project/../mapred/lib/aggregate/ValueAggregatorJob.java at line 137 (see the left-hand side of the figure below for the code block R2-LeftPane).
The cloned block R2-RightPane occurs in a different file with a same name (hadoop-mapreduce-project/../mapreduce/lib/aggregate/ValueAggregatorJob.java). In R2-RightPane at line 139, the code stores a null value and therefore there is no corresponding FindBugs warning.
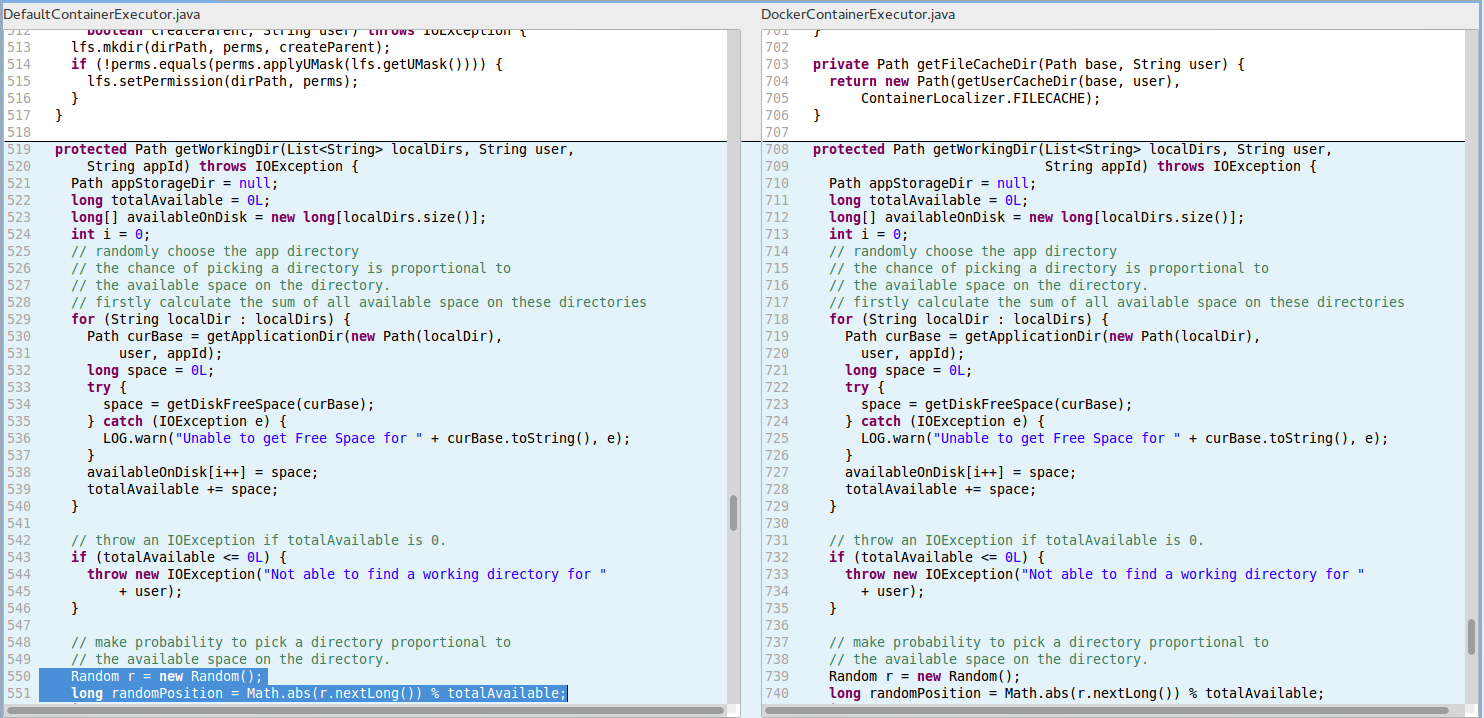
R3. RV_ABSOLUTE_VALUE_OF_RANDOM_INT (Bad attempt to compute absolute value of signed random integer) in the file hadoop-yarn-project/../DefaultContainerExecutor.java at line 551 (see the left-hand side of the figure below for the code block R3-LeftPane).
The cloned block R3-RightPane from the file DockerContainerExecutor.java has the same absolute-value-computation problem and FindBugs gives a corresponding warning at line 740.
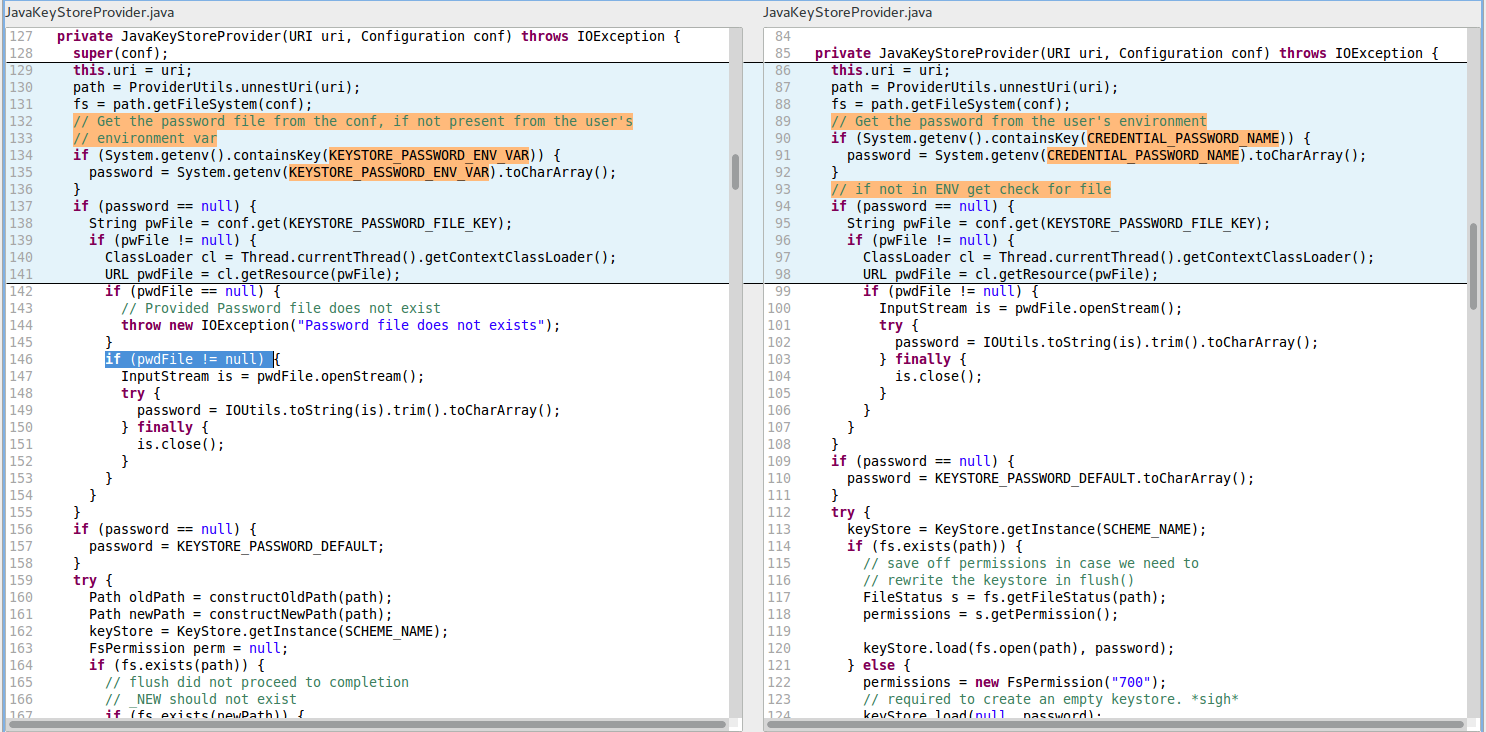
R4. RCN_REDUNDANT_NULLCHECK_OF_NONNULL_VALUE (Redundant nullcheck of value known to be non-null) in the file hadoop-common-project/../hadoop/crypto/key/JavaKeyStoreProvider.java at line 146 (see the left-hand side of the figure below for the code block R4-LeftPane).
The cloned block R4-RightPane from the file hadoop-common-project/../hadoop/security/alias/JavaKeyStoreProvider.java reveals a difference. While R4-LeftPane contains a redundant null check at line 146, R4-RightPane does not test whether pwdFile is null and thus no exception is thrown if the password file does not exist.
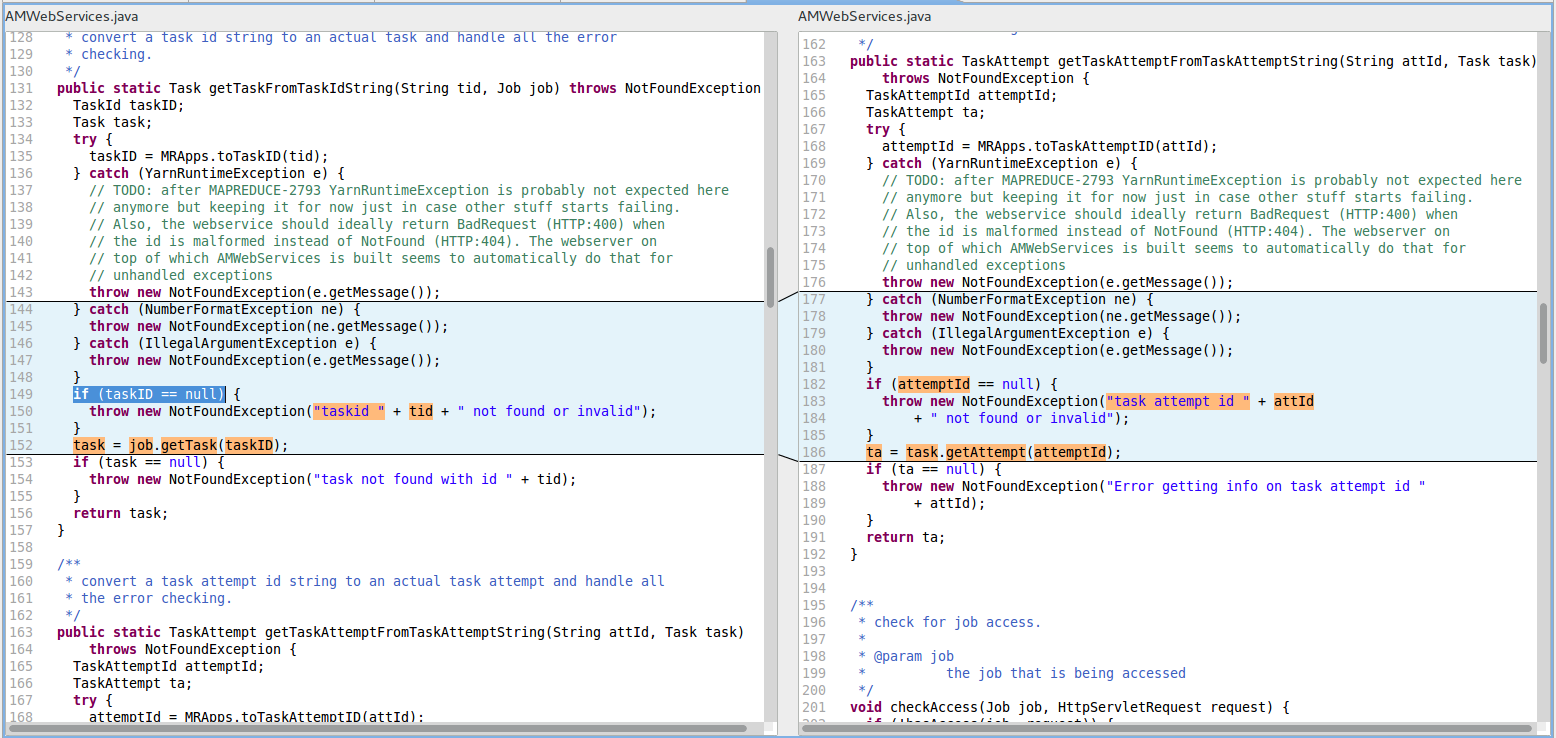
R5. RCN_REDUNDANT_NULLCHECK_OF_NONNULL_VALUE (Redundant nullcheck of value known to be non-null) in the file hadoop-mapreduce-project/../AMWebServices.java at line 117.
The two cloned blocks from the same file appear on the left-hand side of the figure, R5-LeftPane (see line 149) and on the right-hand side of the figure, R5-RightPane (see line 182). Both code blocks trigger corresponding FindBugs warnings.
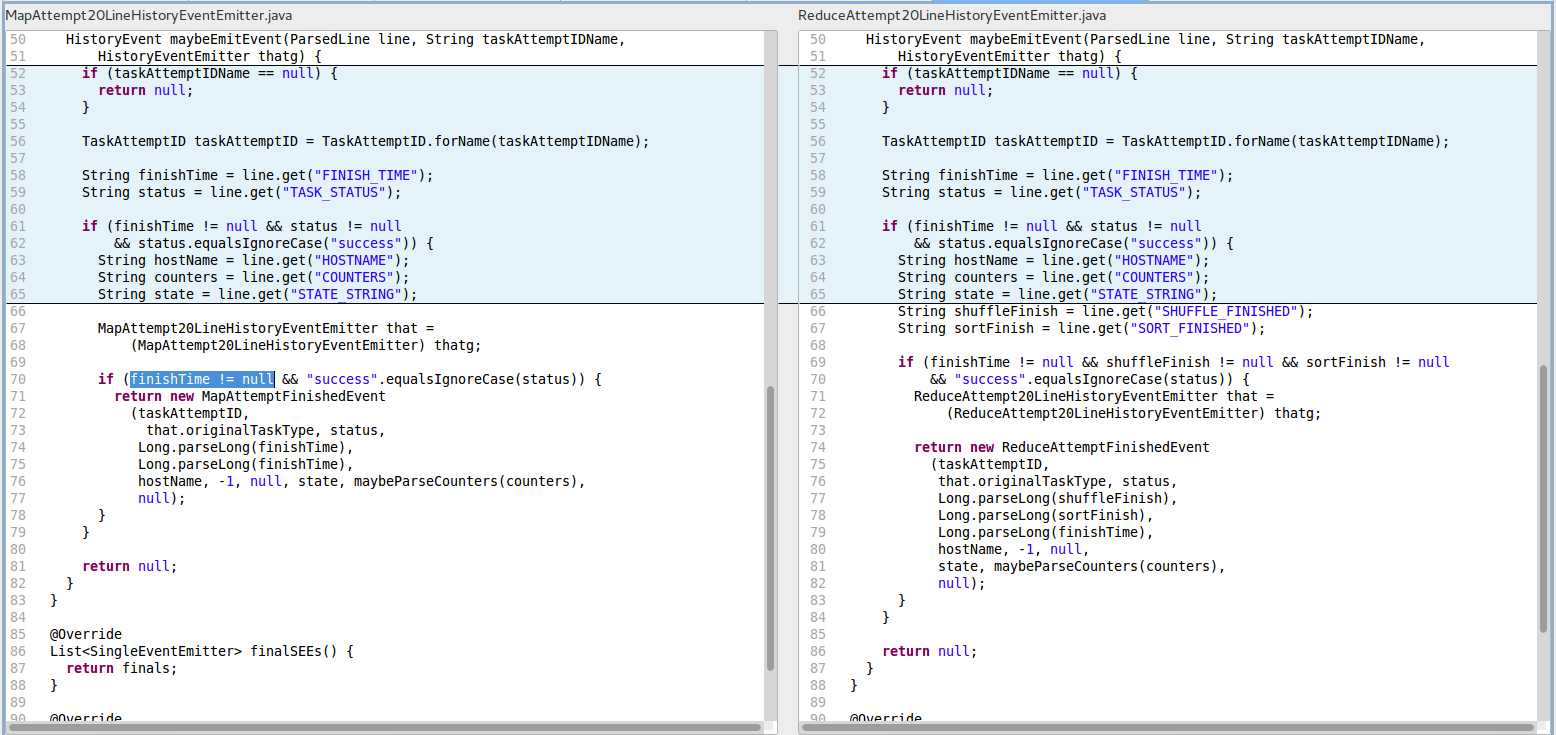
R6. RCN_REDUNDANT_NULLCHECK_OF_NONNULL_VALUE (Redundant nullcheck of value known to be non-null) in the file hadoop-tools/../MapAttempt20LineHistoryEventEmitter.java at line 70 (see the left-hand side of the figure below for the code block R6-LeftPane).
The cloned block from the file hadoop-tools/../ReduceAttempt20LineHistoryEventEmitter.java triggers a corresponding FindBugs warning at line 69.
Summary of the cloned code blocks
For the six reports of cloned code blocks, I observed two patterns:
- FindBugs gives a warning for only one block from the pair of cloned blocks. These cases (
R1,R2, andR4) correspond to either a problem that is fixed only in one of the clones (R1,R4) or a pattern handled differently by FindBugs depending on its syntax (R2). - FindBugs gives warnings for both similar blocks from a clone report (
R3,R5,R6). After inspecting these three cases, I would consider all of them to be worth fixing. I can only hope that these FindBugs warnings will be resolved consistently by the developers. In any case, what I would recommend in all the three cases is to refactor the code to resolve the duplication even prior to fixing the FindBugs warnings.
In summary, having access to and analyzing both the clone detection report and the FindBugs report was helpful in understanding anomaly patterns in the source code of the Hadoop project.
If you want to roll up your sleeves
If this brief introduction to cloned blocks containing FindBugs warnings raised your interest and you would like to roll up your sleeves and do some analyses of your own, here is a topic for future investigation.
- Are there interesting clones of blocks containing FindBugs warnings in the latest stable releases of two other open-source projects, Apache HBase and Apache Hive?
For clone detection you can use an evaluation version of the Teamscale tool that can be downloaded from here (Teamscale is free to use for academic users!).
