-
 Blog
Blog
-
We Will Never Change This Code!

In our code audits we primarily focus on issues that affect the maintainability of the code, e.g., code duplication caused by copy&paste programming. When presenting the audit results, a common reaction by the development team is: »Yes, you’re right. This is ugly. However, it is not a problem for us because we will never change this code!« My reaction: »Great. Compile the code to a binary library and delete the source.« This always provokes second thoughts. Not only because source code also serves as documentation that would be lost but also because the team suddenly doubts its own assessment of the stability of the code. So far, not a single development team followed my suggestion.
With examples of real-world systems this post discusses the multitude of reasons for code to change and explains why the assumption that code won’t change can be dangerous.
Why Does Code Change?
To understand why code changes, I find it helpful to think about a software system as as a mediator between the problem and the solution domain: The software system realizes the requirements posed by the problem domain with help of the solution domain that provides hardware, programming languages, libraries and other base software like operating systems (see figure below [1]). Note that this picture holds for all types of software systems. A business information system, for example, provides functionality to manage insurance contracts (the problem domain) on an Java Enterprise stack on an Intel machine (the solution domain). The automatic cruise control system in a modern car provides driver assistance functionality (the problem domain) on a dedicated control unit running a real-time operating system (if any).
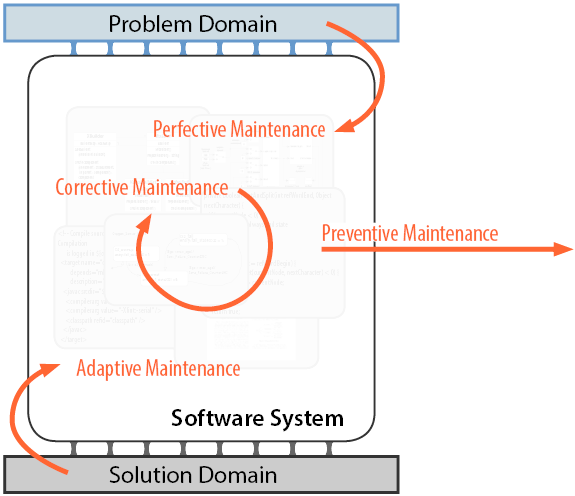
Following this picture, one can distinguish between changes that are triggered by changes in the problem domain (perfective changes), changes in the solution domain (adaptive changes) and changes that have no external trigger (corrective and preventive changes). The following paragraphs give examples for such changes and illustrate why this changes often occur unexpectedly.
Perfective Changes
Perfective changes are changes that modify existing functionality or add new functionality to a software system. This type of change is triggered from the problem domain.
The most simple case of a perfective change is adding a new functionality, e.g., a new report in a business information system. And indeed, given a clean development process, most teams have a good idea of future changes and, hence, know which parts of the code might change and which might not. However, many systems also undergo unanticipated changes, e.g., new functionality requested by a new customer. This again may lead to changes in the code in unexpected places. Moreover, systems are often confronted with cross-cutting perfective changes that affect many areas of the code including the files that were not expect to be changed. Probably, the best known example for such a cross-cutting change is the Y2K issue. In thousands of systems this required updating a two-digit date representation to a four-digit one. One can imagine that this also affected many locations in the code that were assumed to be absolutely stable. A similar change, with a less global impact, was the raise of the VAT rate in Germany from 16% to 19% in 2007. It turned out that this tax rate was hard-coded in various places in many systems that had to be updated accordingly.
So, while some perfective changes and their impact can be predicted fairly well, one needs to be aware that unanticipated changes (often of cross-cutting nature) are not uncommon in many software systems.
Adaptive Changes
Adaptive changes adapt a system to a changing environment. This type of change is triggered from the solution domain, e.g., by modifications to the base technology like operating systems or changes to third-party software. Like perfective changes, adaptive changes also come in two flavors, anticipated ones and unanticipated ones. Good software architectures prevent adaptive changes from rippling through the system, e.g., by encapsulating hardware-specific code in a specific layer. However, this works well only for changes that do not violate the assumptions that were made when the architecture was designed. One counter-example I observed was a memory management layer in an embedded system. A new hardware generation came with an all new flash memory system that promised a significant speed-up for memory accesses. However, in contrast to the old hardware, access times in the new hardware, were highly unbalanced, i.e., reading was a lot faster than writing to the memory. The system could finally benefit from that to gain an overall performance improvement. The changes that were required to achieve this, however, went way beyond the memory management layer as access patterns in many parts of the system had to be redesigned. In general, abstractions meant to encapsulate adaptive changes tend to brake once non-functional characteristics like performance or error-handling are affected. Often, the resulting unanticipated changes affect pieces of code that are assumed stable.
Moreover, the relatively safe world of Java, .Net and the likes cannot be taken for granted. Other, less widespread technologies tend to change more often and more dramatically. In one case that I experienced, the vendor of a proprietary programming languages released a new version of the language that was not fully compatible to the old version. The user of the language, forced to updated due to the end of support for the old version, had to migrate about 1.2 million lines of code to the new version of the language. This update required changes in a large portion of the source code files and could not be fully automated. In fact, a great number of manual changes were required, many of them touching code files that had been be completely stable for almost a decade! Ironically, a number of changes also had to be carried out in dead code, i.e., files that later turned out to be unused. During the migration, however, time pressure did not allow to systematically identify the dead files. So, in this case unanticipated changes were made even more costly by code quality issues (i.e., dead code).
Even if you exclude such dramatic cross-cutting changes, it is very difficult to fully anticipate adaptive changes and their impact due to the complexity of the solution domain of today’s systems. A modern business information system with a central (probably distributed) server and an web interface is built on a incredibly large technology stack that, among others, includes the hardware of the servers and clients, the operating systems, browsers, an execution environment like Java, application servers, database servers, caching systems, load balancers and a plethora of libraries; open-source and commercial. The systems for which we conduct a systematic technology stack evaluation often use dozens of libraries and frameworks. Particularly, in the Java ecosystem is not uncommon to use 50 or more different libraries. The system we analyzed in [2] relies on 87 different JAR files! One can imagine that even the most sophisticated process for managing adaptive changes will not be able to predict their expected impact precisely.
Corrective Changes
Corrective changes are colloquially called bug fixes. This type of change is triggered neither from the problem nor the solution domain but by defects in the system itself. While many systems have a number of bugs no one got around to fix yet, corrective changes are almost always of the unanticipated type. So, how likely is that a piece of stable code has a bug? While certainly imprecise and not generally transferable, reports on defect densities may provide a clue. Even if one assumes a very low density, e.g., the 0.5 defects per thousands lines of code reported for Microsoft products [3], it becomes clear that it cannot safely be assumed that a larger piece of code will never undergo corrective changes.
More importantly, we see many corrective changes that are caused by using a seemingly flawless piece of code in a new environment. One example is code that was designed to be used in English speaking countries only and, hence, does not explicitly deal with different encodings [4]. Once this code is used in non-English context, unexpected bugs are bound to occur. Another example that we frequently encountered in the more recent past, is the reuse of code in Cloud applications. Code that used to work perfectly for years or even decades starts to behave strangely once it is not executed in isolation on a user’s machine but in the data center. Usually, the reason for the unexpected bugs is the code’s complete unawareness for multi-threading and other mechanisms for parallel execution. The static variable or the thread-unsafe library class (Java’s SimpleDateFormat anyone?) that always worked nicely, suddenly turns out to be a huge headache. Similarly, code that was never scrutinized for security problems as it was never executed on a server, suddenly becomes a serious liability when run in the data center. Again, fixing these issues often requires changes to code that was assumed to be stable forever.
Preventive Changes
Preventive changes are changes that prepare a system for other, future changes. This type of change has no explicit trigger but is performed to enhance the efficiency of future maintenance tasks. Examples are restructuring (refactoring), consolidation or redocumentation. In my experience, these type of change is rarely the reason for changes to code that was assumed to be stable. However, this is mainly due to the fact that preventive changes are generally carried out relatively seldom. One example of a preventive change with unexpected impact was the substitution of the old (before Java 8), ill-designed Java date API with the significantly better Joda Time API in a system in the insurance domain. This was a pure preventive change, i.e., there was no outside reason to do it and there were, at that time, no known bugs caused by the usage of the API. The change, however, was never carried out as it would have entailed touching dozens of classes that were assumed to be stable. Apparently, no one dared to touch these classes for several reasons; heavy code duplication being only one of them.
Conclusion
There may be pieces of code that are indeed absolutely stable. However, I hope that this post convinces you that assuming that code will never change can be dangerous as the reasons for code change are numerous, complex and hard to predict. Hence, dismissing findings about maintainability deficits in your code based on the assumption that it well never change is most likely a bad decision.
Nevertheless, be advised that this does not mean you should start fixing maintainability deficits in seemingly stable code right away [5]. This is not only costly but always carries the risk of introducing new bugs in code that might, indeed, not change for a very long time. Instead, always follow the boy-scout rule and leave the camp ground cleaner than you found it, i.e., fix maintainability issues in your code when you have to change it anyway; not sooner, not later.
References
- I first saw this particular depiction of a software system in a lecture given by Markus Pizka at Technische Universität München in 2004 but don’t know where it originates from.
- Veronika Bauer, Lars Heinemann, Florian Deissenboeck: A Structured Approach to Assess Third-Party Library Usage. ICSM 2012
- Steve McConnel: Code Complete, Microsoft Press 2004
- F. Deissenboeck: No Such Thing As Plain Text, CQSE Blog, 2015
- N. Göde: Don’t Fix All Your Quality Deficits, CQSE Blog, 2013
