-
 Blog
Blog
-
What does Code Coverage Really Mean?

The primary purpose of automated tests is to reveal regression bugs. But how can we tell how well a test suite does this? Code coverage measurement is often used to assess tests in practice. But what does it really tell? We analyzed a set of open-source projects to find out and came up with a clear answer. This post summarizes our findings.
If I break this code, will my tests tell me?
When I modify existing code to implement a change request, chances are that I unintentionally break something that worked before. Ideally, an automated test notifies me that I introduced a regression bug shortly after I made a change. A reliable regression test suite thus greatly simplifies maintenance. But how can we tell whether our regression tests are reliable?
A metric commonly used to assess test suites in practice is code coverage. It computes the percentage of code that gets covered (i.e., executed) by the test suite. Its advantage is that it is reatively easy to measure for automated tests (there are tools for this for most popular programming languages). Its disadvantage is that it measures which code gets executed, yet reveals no information about the checks performed during execution: if we remove all assertions from a test suite, it will still produce the same test coverage, yet have a dramatically lower ability to reveal bugs. In theory, test coverage thus provides only an upper bound for regression test reliability (since our tests won’t find regression bugs in code that they don’t even execute).
An approach proposed by the research community to assess test suites is mutation testing. Its basic idea is to introduce bugs into the code and check if the test cases can find them. Its disadvantage is that it is much harder to measure in practice: few mature tools are available (of the five tools we inspected for Java, only a single one could handle our study objects), execution costs are high (in our study, test suite execution was slowed down by a factor of up to 2700) and the technical details of mutation analysis are cumbersome (choice of mutation operators, handling of equivalent mutants, …). While more meaningful, its application in practice is thus orders of magnitude more expensive than code coverage measurement.
So when is measuring code coverage good enough? To find out, we compare mutation testing results with code coverage metric values for a range of open source systems to better understand what code coverage really means for regression test reliability. The study is part of the Master’s Thesis of Rainer Niedermayr (refer to his thesis for additional details on the tools, his study design and so on).
Pragmatic mutation testing
Whether a test detects a bug depends not only on the test, but also on the bug. It thus matters which changes (or mutations) are performed during mutation testing. For our study, we decided to perform the largest change we could think of: remove all of the code of the method under analysis. Our basic intuition is this: if a test does not notice that the entire code in a method has been removed, it cannot be relied upon to detect smaller changes in its previous behavior, either.
So to measure the bug discovery rate of a testsuite for an application, we ran the following analysis for each method in the application that gets covered by its tests:
- Create a mutated version of the application for which this method has an empty body
- Run all test cases that execute this method
- If at least one of the test cases fails (but passed with the original method), we classify this method as checked, otherwise as unchecked.
The discovery ratio is computed as (# checked methods) / (# covered methods) and denotes the probability that the test suite can detect if we remove the code from one of the methods it covers.
We regard this discovery rate as an upper bound of the probability that the test suite discovers a regression bug. Upper bound, since defective changes in practice can have more subtle consequences, than entirely removing the behavior from a method.
How meaningful is test coverage for unit tests?
We computed the bug discovery rate for these projects with unit tests:

The higher the bug discovery rate and the more similar the results, the better can we use code coverage as an approximation.
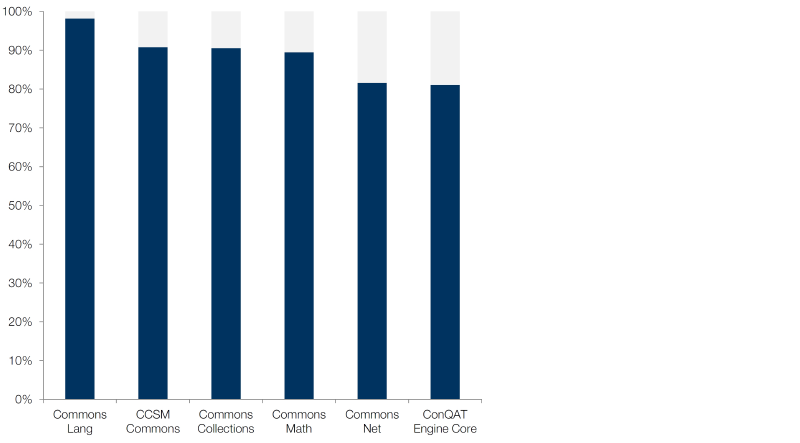
Depending on the analyzed system, 82% to 98% of the methods executed during tests were actually checked: the introduced bugs were discovered. We manually inspected the unchecked methods. Many of them contained code used for debugging, such as toString() methods only executed for writing dumps. We can thus argue that the test reliability of important code is still higher. In a nutshell, most of the executed methods were actually checked. For unit tests, code coverage is thus a meaningful indicator of their regression test reliability.
How meaningful is test coverage for system tests?
We performed the same analysis for applications with system tests:

While unit tests execute small code fragments (such as one or several methods), system tests execute a substantial part of an application. A single system test typically covers hundreds or even thousands of methods.
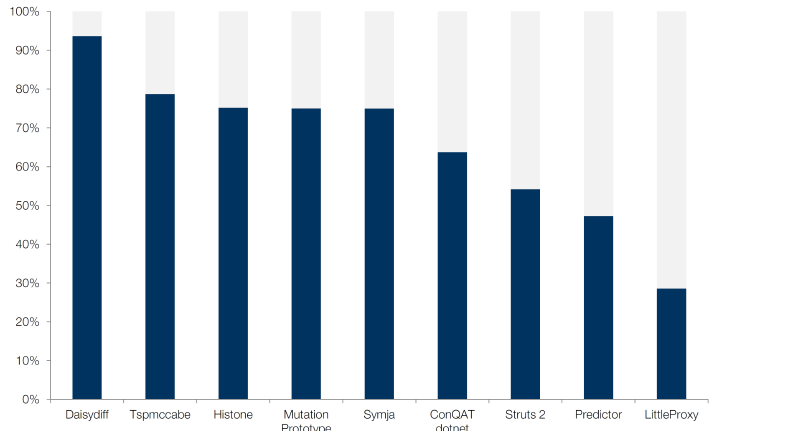
For system tests, the bug discovery rates vary strongly across systems. While some have rates comparable to unit tests, the lowest rate was 28.5%. In other words, there was a 71.5% probability that the system test suite would not have noticed, if we would have deleted a method’s body entirely. In this system, code coverage is thus deceptive.
Code coverage is thus an insufficient indicator for regression test reliability for system tests.
Lessons learned
With regard to the original question:
For unit tests, code coverage is a useful approximation of regression test reliability.
For system tests, code coverage is not a useful approximation. To determine their discovery rate, we need to resort to other means (such as mutation testing or manual inspections).
When measuring test coverage, differentiate between different test types (i.e. unit, component, system) to allow for meaningful result interpretation.
We furthermore learned:
Mutation testing is hard. Most existing tools are academic prototypes not ready for the real world (they do not terminate, throw cryptic internal exceptions, run only on a tiny percentage of the code or take ages; typically a combination of the above.)
Not all untested code is worth testing. Some is too trivial to test (e.g., plain getters and setters); other code is used only for debugging or diagnosis. Since consequences of bugs in debug or diagnosis code are typically less severe than in other code, the effort to write and maintain automated tests for them is often not justified. Interpretation of code coverage (and mutation testing) results must thus take the analyzed code’s purpose into account.
Details
The remainder of this post summarizes technical details of the study. Refer to Rainer’s Master Thesis for details.
Our mutation testing approach uses only a single operator: remove method body. More advanced mutation testing approaches offer numerous additional operators. We chose this approach for several reasons.
Adding mutation operators increases the number of mutants one needs to analyze. Execution costs quickly get prohibitively expensive for practical use (even our simple approach, which creates no more than two mutants per method, slowed down test execution by a factor of up to 2700.)
The smaller the change a mutation operator makes, the higher the probability that it changes only the syntax, but not the semantics (e.g., by changing an unnecessary statement in a method, such as an assignment to a variable that is never read). Test suites cannot detect such mutations. These cases (called equivalent mutants in the literature) make result interpretation difficult, since they appear to be holes in the test suite, but are really weaknesses inherent to mutation testing. Since our mutation operator made large changes, we encountered few equivalent mutants. Sufficiently few that we could deal with them manually.
So how does the mutation operator work exactly? It depends on the return type of the methods:
Void: We simply replace the method body with a return statement.
Primitives (int, bool, …) and Strings: We replace the method body with a return statement that returns a fixed value (e.g., 15323 for int). Since we might accidentally hit the value a test expects (especially for bool return types), we create two mutants. Each returns a different value (i.e., one for true and one for false for bool methods).
Objects: We ignore these methods, since we don’t know how to create valid instances. Simply returning null will not work, since many tests will fail due to null pointer exceptions. However, this does not tell us that they really perform any checks on the objects they receive.
We thus limit the analysis to void and primitive methods. What does that tell us about methods returning objects? To find out, we manually implemented factories that create valid object instances for three of the study objects. While there are small differences between the method categories, the results are comparable.
There are some methods that are too trivial to justify testing efforts, such as getters and setters in their simplest form. We ignored these in the analysis.
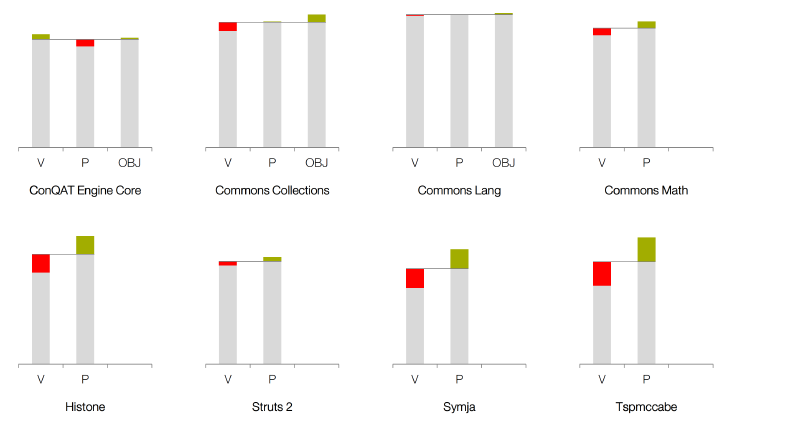
The figure shows the discovery rate by return type categories: »V« stands for void, »P« for primitive and string, »OBJ« for objects. The colored bars indicate the deviation from the aggregated discovery rate of the project. The red bar expresses, how much worse is, the green bar respectively denotes positive deviation. We implemented factories for the first three projects. While there are differences between the categories, differences across projects are larger than across categories.
