-
 Blog
Blog
-
Teamscale for Structured Text

Many static analysis tools excel at analyzing code that is written in popular programming languages like Java and C# for which there are tons of freely available resources like code examples and documentation. There is a substantial common understanding of coding best practices, frequent pitfalls and recurring code smells. In addition, existing libraries to parse and analyze code written in these programming languages make it easy to support these in a static analysis tool. So does Teamscale.
However, there is a large number of programming languages like Structured Text and Magik that are less popular but, nonetheless, highly relevant for certain domains. Maintenance of code written in these languages faces the same challenges as maintenance of code written in more popular languages. Hence, continuous quality improvement of this code is just as important as for other languages. Unfortunately, most static analysis tools fail when it comes to analyzing these languages because they either do not support the language at all, or the feature set becomes very thin.
With Teamscale we aim to support these languages just as well as we support popular languages. That means Teamscale provides its core features like incremental analysis, findings tracking, time travel, baselines, delta analysis, blacklisting, metrics and clone detection, for all languages in the same way. This applies, for example, to Structured Text specified by IEC 61131-3.
Structured Text (ST) is a programming language used for programmable logic controllers. An ST system is organized in program organization units (POU), which can be either a PROGRAM, a FUNCTION or a FUNCTION_BLOCK. These are the elements recognized by Teamscale (like classes in Java). The POUs are usually stored as files in a version control system. Depending on the IDE, the files are usually either plain code files, or XML files that contain meta information together with the code. Both alternatives are supported by Teamscale.
I use two slightly modified examples from Wikipedia to illustrate how ST looks in Teamscale.
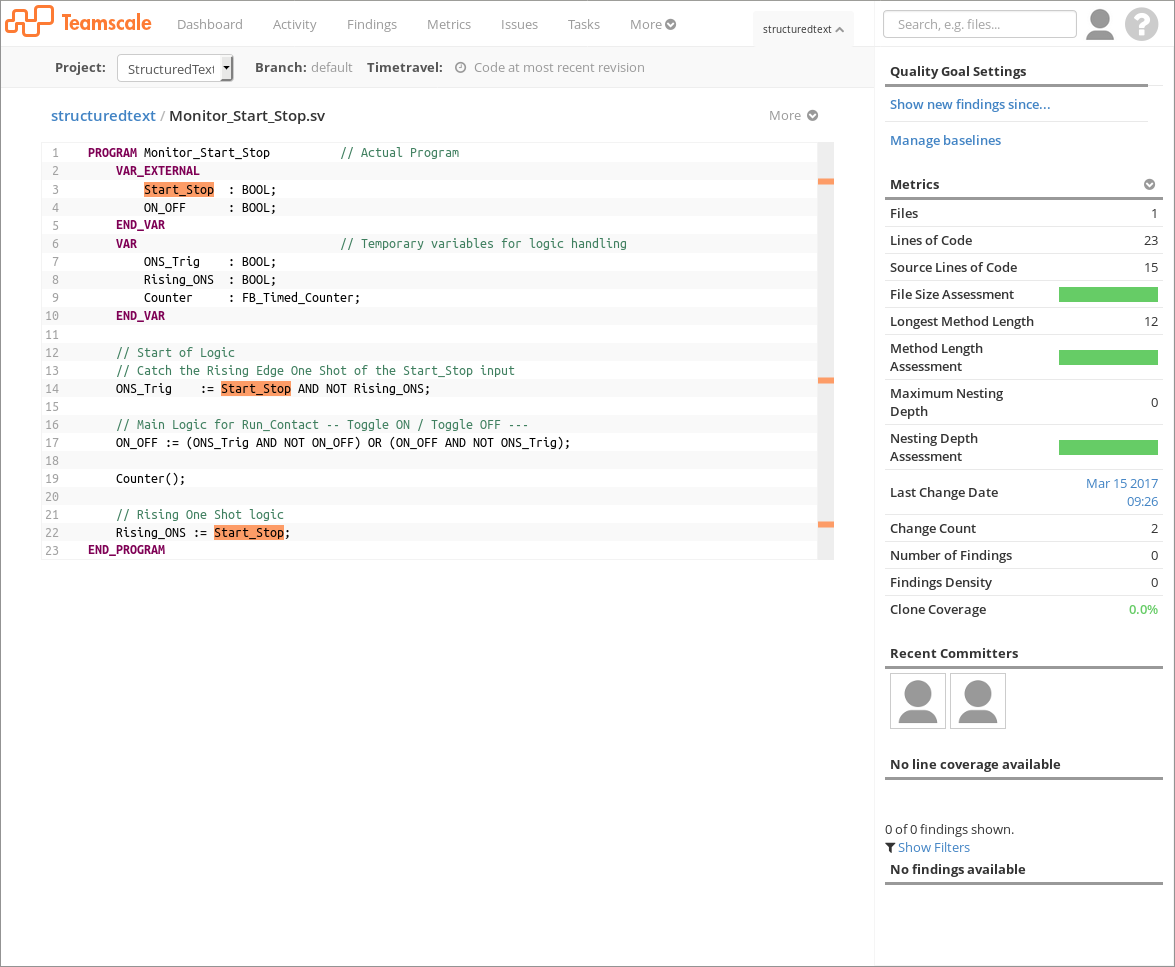
As you can see from the first screenshot, ST code is presented just like any other code in Teamscale. It is syntax highlighted and comes with all the metrics that you know from other languages. It also benefits from Teamscale’s identifier highlighting such that you can select a variable in the code and all other references are highlighted for easier understanding.
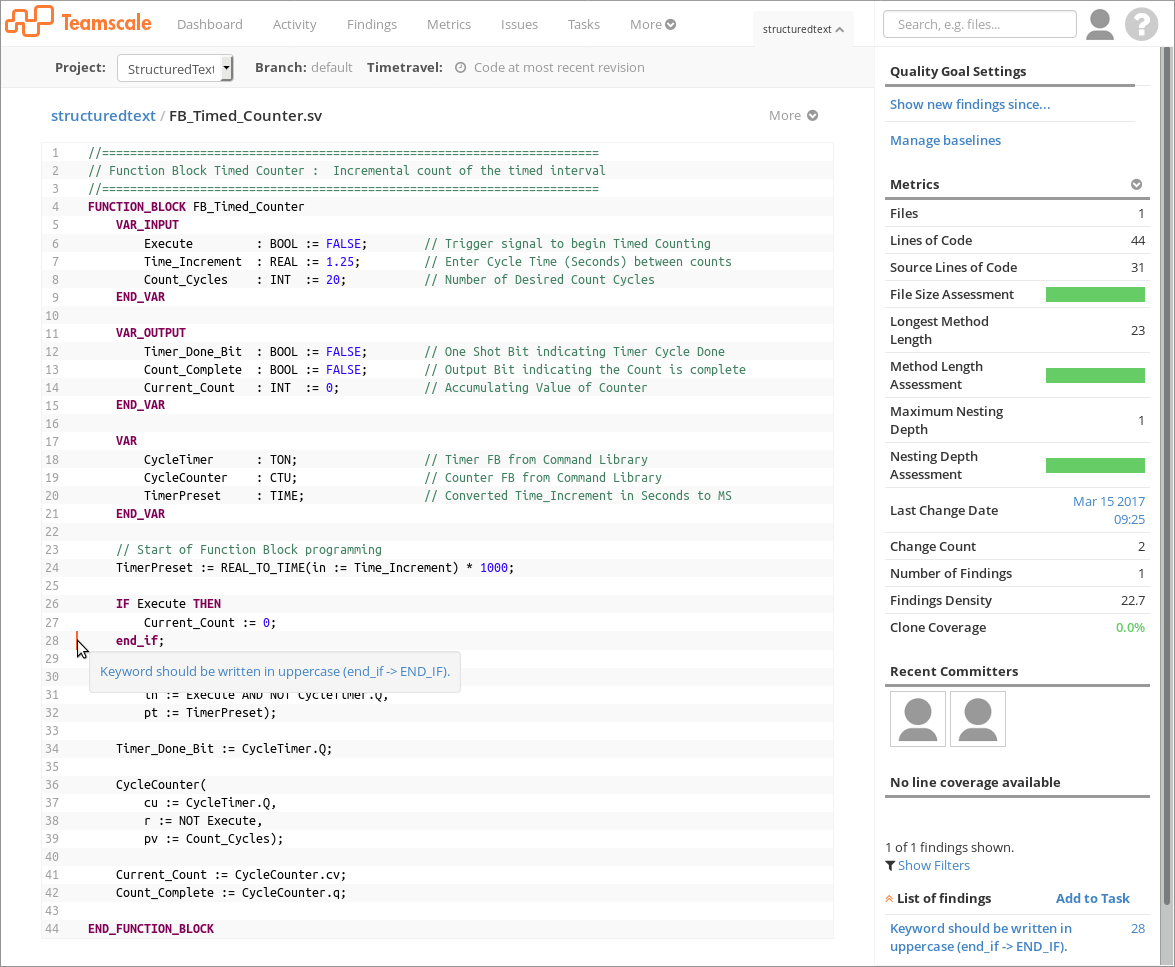
The next screenshot shows that findings are also displayed as for any other language. Of course, individual findings are tracked and can be blacklisted. In this example you see the result of a check that we have implemented specifically for ST code. The check requires all keywords and operators to be written in uppercase letters and creates a finding if that is not the case. Of course, you can disable the check in the analysis profile if it does not apply to your setting.
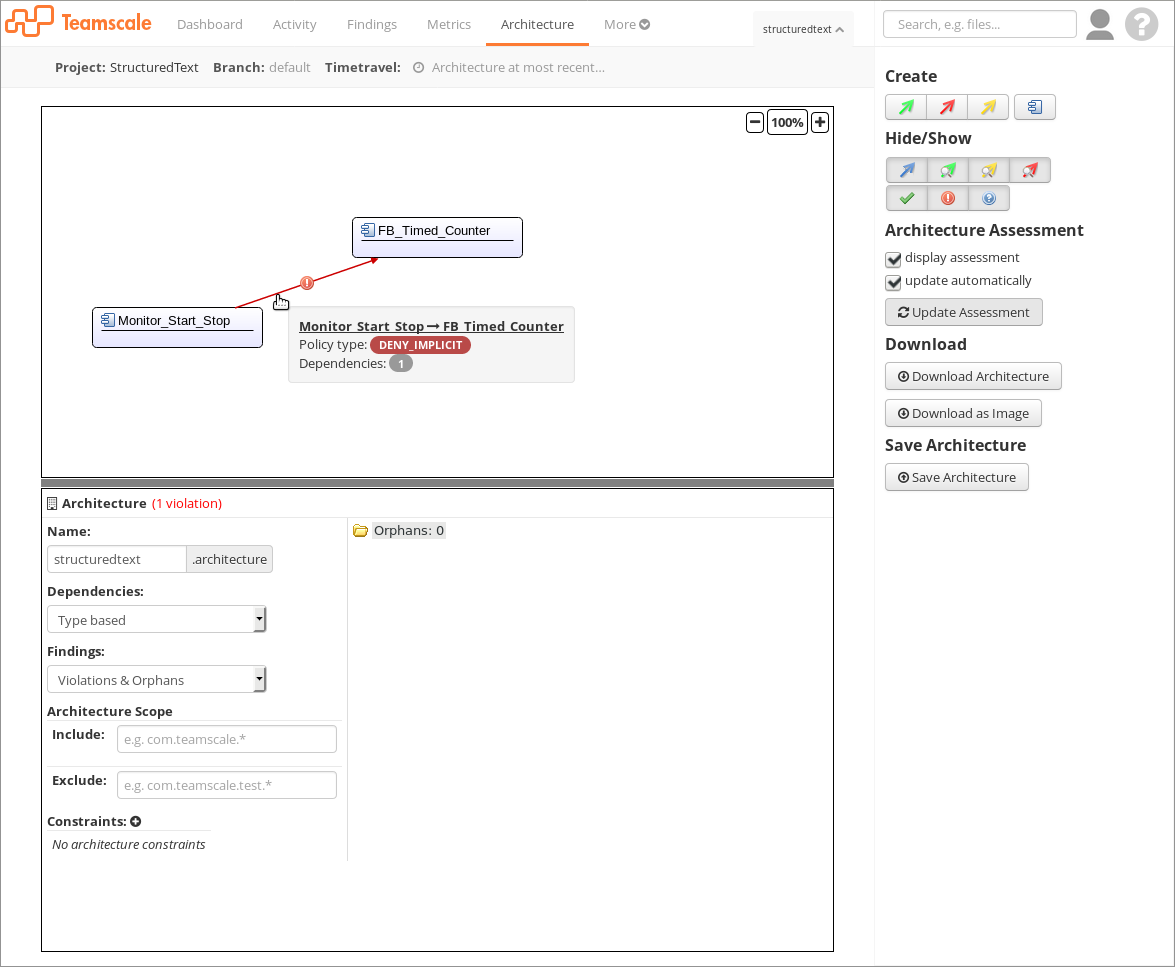
The final screenshot shows how architecture analysis looks for ST. Again, there is no significant differences to other languages. The POUs are the types and the control flow (calls) to other POUs are the dependencies.
Try it
If you’d like to try Teamscale on your own ST code, feel free to download Teamscale and request a free evaluation license. We are also happy to support you in setting up Teamscale. Especially for ST we have seen that many IDEs store the POUs in a custom file format that might not work with Teamscale out of the box. But adding support for these file formats can usually be done quickly.
If your code is in another programming language, which is not yet supported by Teamscale, don’t hesitate to contact us. We have a lot of experience in adding support for new languages and would be happy to discuss this with you.
