-
 Blog
Blog
-
Success Factors for Continuous Integration and ...

Continuous Integration (CI) is one of the dominating terms when talking about software engineering methods with developers. The initial idea behind continuous integration was merging the changes performed on developers’ working copies several times a day, in order to prevent integration problems. By keeping the changes since the last integration small, new integration problems are much easier to analyze and to solve and thus the »integration hell« becomes less scary.
In software-engineering projects, establishing at least a nightly or daily build is quite standard, more ambitious teams even trigger their build after every commit to the version control system. Besides pure integration, many times automated tests are also executed. Thus, not only integration problems detected by compiling or linking the code are identified, but also misbehavior at runtime.
A common problem is that builds compiling and testing big systems become very long running. In the words of Martin Fowler:
»Nothing sucks the blood of a CI activity more than a build that takes a long time.«
We have often seen the solution (or compromise) of distinguishing long running tests from the faster ones, e.g., fast unit tests and long running UI tests. The long running tests are then executed on a separate build (less frequently) in order to preserve a quick feedback on compiling issues and failing of the fast tests.
Continuous Static Analysis
After executing tests in the build, integrating static-analysis tools is often the next step on the CI agenda. Depending on the complexity of the analyses and the size of the code base, such tools have an execution time up to several hours for large systems, so this often causes another compromise in getting rapid feedback.
Even more critical is the fact that the »defects« detected by static analysis tools differ from defects identified by failing tests or non-compiling code: Especially on »grown« code, static analyses will create an immense findings flood, thus making the build break is usually no option. Even for very clean code bases it is often annoying if the build breaks for every little badly formatted identifier or cloned code, especially in the presence of false positives (which cannot be avoided completely). Furthermore, these findings are often due to unfinished work in progress and subject to a clean-up later on. As a broken build should be an alarm signal for the whole developer team, if it happens too often, this signal will not be regarded as really urgent anymore.
Incremental Analysis
Although using static analyses is an advancement on the way to better code quality, there are better ways to execute them as in the build. We also integrated our tool ConQAT into the builds of many projects (usually without making the build fail). However, we had to learn that this does not really have an effect on the developers’ behaviour and on code quality. Much more promising are the results gained from using incremental analysis in Teamscale that are directly triggered by commits on the version control system (documented, e.g., in this article on experiences from a development project at Audi). This approach has three main advantages:
- the analyses provide rapid feedback (within seconds)
- the feedback is personal to the developer causing findings (not the whole team gets disrupted)
- the build becomes faster without executing analyses tools
In a simple set-up, the build is not involved at all in executing the analyses. As depicted in the following figure, the feedback to the developer is not only faster using incremental analysis and provides a personal feedback to its author because every individual commit is analyzed. The Teamscale server always has up-to-date analysis results, these can be pushed into the developers’ IDEs every time a source file is opened. This makes the findings of the analyses much more visible to developers compared to publishing them only in some browser-based quality dashboard. Furthermore, no execution of the analyses on the developer’s local machine needs to be performed.
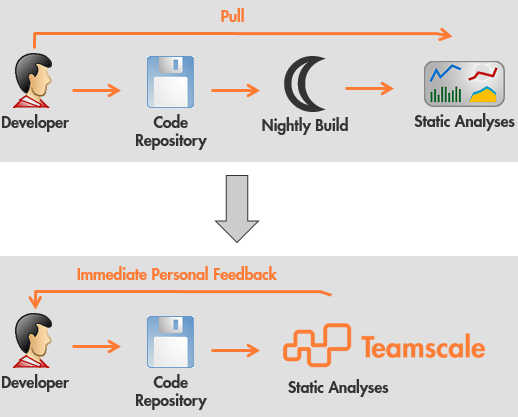
Teamscale uses results from the build only for getting results from measuring test coverage (performed by external tools). Often, we also integrate results from external analysis tools that run on bytecode.
