-
 Blog
Blog
-
First Steps of Code Quality Analysis for SAP HANA ...

During the last years, we have deeply integrated analyses for ABAP in Teamscale (and formerly in ConQAT). These analyses are used by SAP customers to keep the quality of their custom code high. However, since SAP is introducing many new programming technologies, more and more SAP users are confronted with new languages besides ABAP. One of these is SAP HANA SQLScript, which is used to develop high-performance stored procedures for the SAP HANA in-memory database. Unfortunately, SAP did not provide any static code analysis for SQLScript (in contrast to SAP Code Inspector for ABAP). Moreover, there are no precise guidelines how to develop good SQLScript code so far. In this post I’ll present our initial thoughts on assessing the code quality of SQLScript.
Our starting point to identify relevant static checks was the SAP HANA SQLScript Reference, which already mentions some (very general) best practices (chapter 13). Some of the recommendations there are very easy to detect automatically, e.g.
- Avoid using cursors
- Avoid using dynamic SQL
Creating checks for these two was fairly easy using Teamscale’s custom checks framework. Basically this is just a search for the respective statement (e.g. DECLARE CURSOR, EXEC or EXECUTE IMMEDIATE).
Complex SQL Statements
The first rule in the SAP best practices is more interesting: Reduce complexity of SQL statements. Here, the recommendation is to extract sub-queries from complex queries and assign these to table variables. Sub-queries are SELECTs which occur within an outer SQL statement. These can be used in most places where a table name could be used, especially after the FROM clauses. Since sub-queries can be as complex as any SELECT statement, and may contain sub-queries again, the heavy use of sub-queries may result in code that is unreadable.
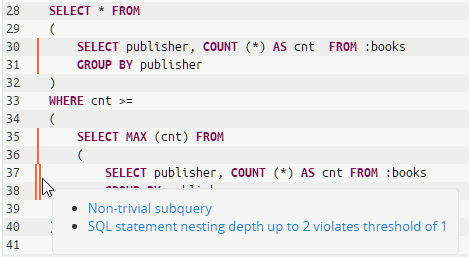
Here is an example of nested queries (adopted from the SAP HANA SQLSCript Reference):
SELECT * FROM
(
SELECT publisher, COUNT (*) AS cnt FROM :books
GROUP BY publisher
)
WHERE cnt >=
(
SELECT MAX (cnt) FROM
(
SELECT publisher, COUNT (*) AS cnt FROM :books
GROUP BY publisher
)
);This can be improved by extracting the sub-query (note: the same sub-query is used twice here).
books_per_publisher =
SELECT publisher, COUNT (*) AS cnt FROM :books
GROUP BY publisher;
SELECT * FROM :books_per_publisher
WHERE cnt >=
(
SELECT MAX (cnt) FROM :books_per_publisher
);The extraction of sub-queries will result in more comprehensive programs: Using descriptive names for the table variables increases the readability of the code a lot, since it documents the intention of the sub-query. Thus, it would be good to have automatic checks to avoid such complex SQL statements. To cover this demand, we have derived checks to identify
- Non-trivial sub-queries
- Deeply nested sub-queries
- Sub-queries without parentheses
Let me explain these checks in more detail.
Non-trivial Sub-queries
Since there is hardly any benefit to extract very simple SELECT sub-queries (e.g. selecting rows from a table only), a check which reports any sub-query is not very useful in practice. Only non-trivial sub-queries should be regarded as finding. Thus it is required to distinguish between trivial and non-trivial sub-queries. For now we applied the following definition: Non-trivial queries are either nested or contain any of the following clauses: WHERE, JOIN, GROUP BY, HAVING or UNION. Otherwise the sub-query is regraded as trivial.
Deeply Nested Sub-queries
Sub-queries may recursively contain sub-queries, which make the code even harder to understand. Thus we’ve added a separate check to identify deeply nested sub-queries. The nesting depth level is configurable. In contrast to the check for non-trivial queries (which already covers nested queries) this checks allows explicitly identifying deeply nested queries, which can be reported with higher severity (e.g. red instead of yellow) in Teamscale.
Sub-queries without parentheses
A third check came to life as a side-effect during implementation of the complex sub-queries checks, since it backups the detection of sub-queries: The check searches for sub-queries, which are not enclosed in parentheses. Usually all sub-queries should be enclosed in parentheses, otherwise it is hard to understand which clauses belong to the sub-query and which to the surrounding query. This check reports missing parentheses, but it can be suppressed for specific SQL statements (e.g. within INSERT statements).
The result of the checks are findings like these:
Built-In Analysis
With the general support of SQLScript, the built-in analyses of Teamscale are also available:
- Duplicated Code
- Deeply nested procedures / functions
- Long procedures / functions
These analyses complete our current quality indicators for SAP HANA SQLScript. For now, we are still evaluating the practical use of these checks with experienced HANA developers and probably we will add some more specific checks for HANA code, until the current checks are included in the official Teamscale release. Furthermore, we are also integrating checks for HANA View specifications. You can subscribe to the Teamscale newsletter to get informed about the availability of the HANA support in Teamscale.
Comments are highly welcome!
