-
 Blog
Blog
-
One metric to rule them all

If you are interested in improving the quality and specifically the maintainability of the software you produce, then you will have very likely asked yourself one of these questions:
- How well is my system doing in comparison to others?
- Which of our projects are not doing so well?
- Where do I have a serious problem and need to act right away?
- How can I make sure that my system is improving over time?
And most likely, you will also have asked yourself: Is there not one single number that can answer oll of these questions for me? I.e. can we take all the complex quality measurements that are possible (clone coverage, test coverage, structure metrics, open field defects, pending reviews, …) and aggregate them into one KPI?
It is essential to clearly define your goal
We all wish for such a number but we often don’t question what our real goals are with it. Indeed, many schemes to arrive at such a number have been developed without ever questioning for a single second what that number should actually achieve – which questions it should answer.
I know I always imagine it like the surveys you see in many magazines on computer hardware. Where different CPUs or printers or what-have-you are compared according to their specs and then get a final score from 1 to 10, easily telling you which is the worst and which the best. But then you find out you don’t actually care about double-sided print and that the best printer can’t even print your holiday pictures.
So before we jump into different aggregation techniques let’s look at some of the main reasons we have found why people crave such a number:
- We want to assess the current situation in our project or company
- We want to ensure continuous improvement in our project
- We want the number to inform our long-term planning decisions
I’ll go into each of those goals in detail below. As we’ll see then, they cannot all be answered effectively with the same number (unfortunately), but there are nonetheless good techniques to achieve these goals.
How can I assess the current situation?
The usual question people want answered here is: Which of my projects are currently going south? Or in other words: tell me if there is an immediate need for action in any of my projects.
A bad way to answer this question is to take all the metrics you can get on your project and take their average (or weighted average if you’re fancy). Why? Because any averaging of values means we lose all information about the variance in our data set. Which in turn means that we might not be able to detect any outliers. Take a look at the following two systems:
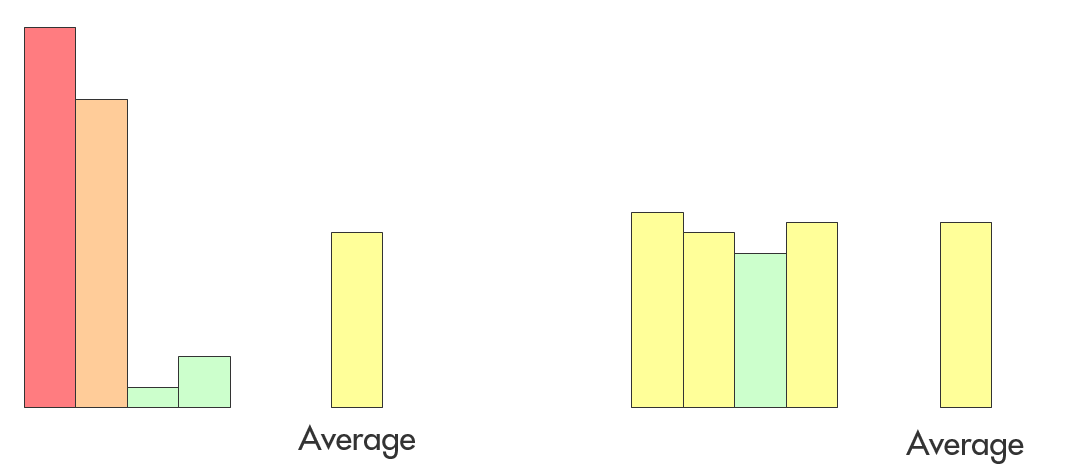
This graphic shows two different systems where we measured and assessed four metrics each. The colors of the bars show the assessment that was given to the measured metric, ranging from green (not a problem) to red (critical problem)
They both have the same average value across the four KPIs shown here, even though one of them is completely average while the other has major problems in two areas. The good values in other areas have masked these grave problems. When you’re trying to asses the need for action, that’s not at all what you want.
Instead, we recommend you first assess the need for action within each metric separately, then take the worst assessment for each system:
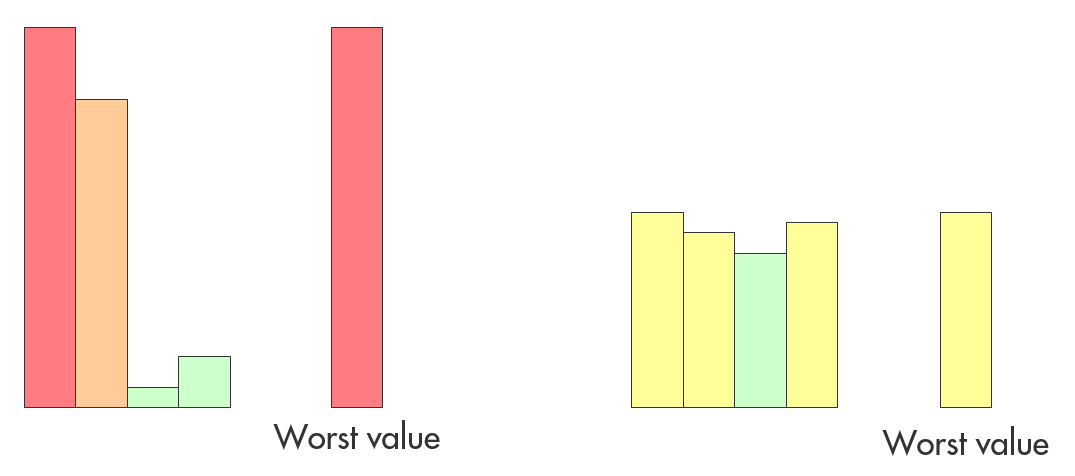
After all: if there is a need for immediate action shown by one metric, there is a need for immediate action in that project. Regardless of how good the rest is. We have been using this technique successfully in our audits for a long time. It helps our customers prioritize where to expend effort in the short term to actually make long-term improvements possible. For example, say you have no unit tests at all: it probably makes sense to invest here first, before fixing your architectural problems.
How can I ensure continuous improvement?
That’s the job of your QA process. To help with that, we define quality goals that clearly define the effort that should continuously be expended towards maintaining or improving software maintainability. Do you want your system to just not get any worse or do you want to gradually improve its quality? Or is it even a green-field project and you don’t want any problems at all?
Once you have set a quality goal for yourself, all the problems that you introduce into your code base or fail to clean up when you should have can easily be measured. We call these quality goal violating findings. Looking at this number for short time intervals is a good indicator as to how the team is currently adhering to the QA process. If it goes up unexpectedly, you know there’s some external factor putting pressure on your team. Like that new feature that has to be finished yesterday, for example.
No matter how well we try to do our jobs, there’s always some problems that we don’t have time to deal with. This, in addition to the quality goal violating findings above, it makes sense to gather all the neglected findings in longer intervals and decide what to do with them. We do these in our quality reports. These also give you a good sense of the current status and development of your system.
How can I inform my long-term planning?
In the long-term, you’ll want to decide how much effort to put into your system. Whether you’ll need any major clean-up operations. Or if you should just scrap the system entirely and start a rewrite. For these kinds of major questions, automatic metrics are certainly a first indication, but a more detailed look at the system in question is definitely due.
Most importantly, a lot of important factors in these decisions can’t be measured automatically. Is the system’s overall architecture still adequate for the problems we’re facing? is one of them. I would even argue that the really interesting questions here can only be answered by a human looking at the system and its surrounding development process. Thus, it’s no surprise that we recommend you do an in-depth audit of your system before taking these important decisions.
The leaderboard
As you’ve seen, there is a technique to give you insightful data for each of the three questions we have posed. Nonetheless, many people are still very attached to the idea of a leaderboard, where applications are ranked best to worst. And I can understand that - it’s an appealing idea. It may inspire some amount of competition between projects to be on top of the board. I myself, however, have mostly found these kinds of tables to be between hard and impossible to interpret, misleading at times and certainly lacking all context. Here’s an example of some open source systems I quickly put together:
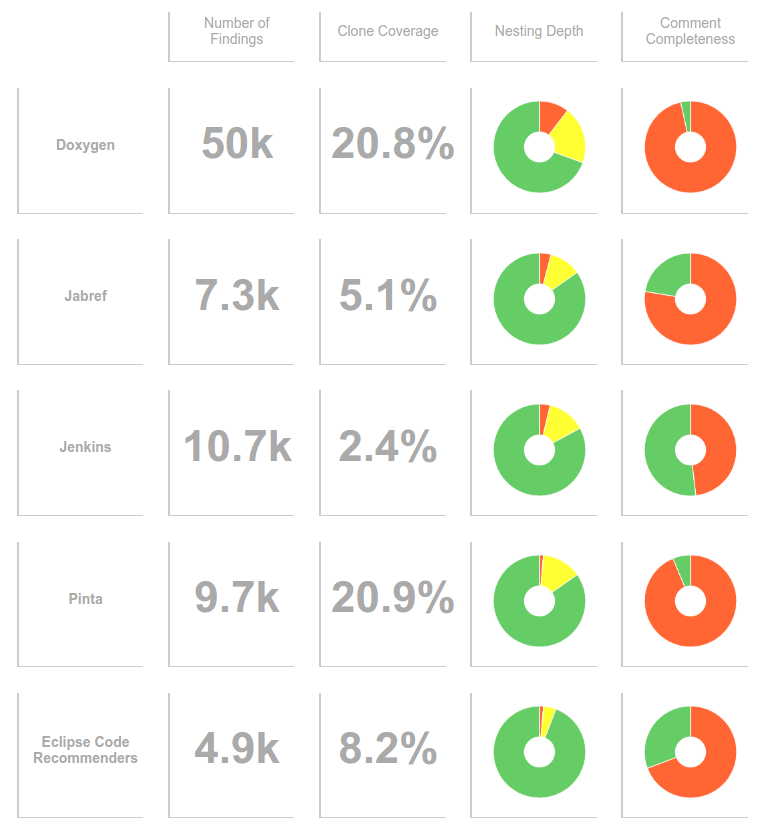
I don’t know about you, but I don’t find this easy to read and I certainly have a hard time sorting these systems best to worst. Which is better? Jenkins with the better documentation and clone coverage or Eclipse code recommenders with the lower number of findings and better nesting depth? And did you know that Pinta’s 9,700 findings are to a large part caused by generated code? Neither did I just from looking at that leaderboard.
Worst of all, some people will take this kind of ranking way too seriously and prioritize getting to a high position above all else. Because it makes their project look good. Not because it makes economical sense to do. Aggregating these many metrics into one, e.g. by taking the (weighted) average, will not help either. Aggregation without a clear goal, as I said above, leads to a number that doesn’t answer any of your questions. Or worse: you think it does but it actually doesn’t, meaning you make the wrong decisions in the long term.
To leave you on a bright note: what we did find useful is to rank applications within one metric. This benchmark allows us to rank systems relative to each other based on one metric, e.g. clone coverage, and give you your rank or percentile on the list. Once you know your rank for a range of metrics, it gives you a good sense where your system’s strengths and weaknesses are, compared to other, similar ones.
In conclusion
Aggregation means a loss of information. Thus, the goal of the aggregation has to be crystal clear or we’ll accidentally aggregate away the most important bits. Furthermore, different goals obviously warrant different aggregation techniques, not all of which are as simple as an automatically calculated weighted average.
Most of us will be interested to know which systems are currently going south, i.e. need immediate action. For this, we recommend you judge the need for action within each metric you have available and then take the worst value for the entire system.
While we’re busy developing our system, we’ll want to make sure we’ll meet our quality goals. Here, it makes sense to have a look at the number of quality goal violating findings in short intervals and have regular quality reports in longer intervals.
For long-term planning, many factors are vital which can’t be measured automatically. A detailed audit of the system is best to capture and aggregate those factors so they can serve as a basis for a management decision.
There are many reasons to want a leaderboard of all your applications but you won’t be happy with it unless you are 100% clear on the goal you want to achieve with it and choose the right aggregation technique to distill useful information from it.
