-
 Blog
Blog
-
Why We Moved to Feature-branch-based Development

My colleague Martin already explained our journey to Git in his blog post. I would like to shed light on our motivation for that change and the experiences we made from a more methodological point of view. Furthermore, I would like to point out that we did not only exchange a versioning system but also changed our development process in a severe manner.
The problem: Why did we change our development process and version control system?
Our development team grew: We started developing Teamscale within a research project and with about two colleagues working on the codebase. That time we did not have much time-pressure, no customers demanding new features or complaining about bugs. Thus, the most effective way of collaboration was directly working on trunk in our Subversion repository. This way we did not need to merge anything and we always had the latest features when we ran the build. We used branches only for stabilization of releases. This worked fine in the beginning. However, as we launched Teamscale, times changed: Together with the Teamscale’s success, the requirements on our development process grew together with our team-size. Within three years we increased the size of our development-team by about a factor of 10. As a consequence our code churn heavily increased and we were working on many more different features in parallel.
Need for more stable development versions: In the beginning every developer had a rough imagination about what resides in the head-revision of trunk and could estimate how stable it was. Then we began to have the first development partnerships with customers that served as a basis for developing new features. This was when we encountered the problem that we wanted to ship new versions on a short (weekly) basis in order to have our partners use these new features and provide feedback. As they often used it as a productive Teamscale-instance, they had a huge demand on stability. However, due to many parallel activities, trunk was not always in a good condition. This resulted in instabilities that were caused by unfinished features and code that had not completely gone through our review and testing process yet. When we began to use separate customer-branches for every development partnership, we ran into the problem that these branches did not contain fixes for known bugs although these were already eliminated on trunk.
Continuous Delivery: Every developer probably knows the situation that features that sounded feasible when designing them, become more complex and time-intensive when facing unforeseen special cases and additional complexity when implementing them. Such issues in many cases caused us to shift release dates – at first only few days, but it became worse: We developed very cross-cutting feature sets (e.g. Teamscale’s branch support mentioned below). After testing them we still had doubt about their maturity in terms of stability and feature-completeness. Close to a release date we thus decided to do backports of other features and fixes our customers were waiting for to the branch of our former major release. As this caused much effort and frustration, we decided that we needed to get our planning sovereignty back: Single features should not be able to re-determine our release dates anymore and we wanted to deliver faster!
Our solution: Feature branches!
When we moved to Git we introduced a radical feature-branch-based approach. We use an individual branch for every feature and even every single bugfix and use a strict naming scheme for the branches based on the ticket-ID from our issue tracker. Before merging changes to our master all our QA-activities must pass: the build must be successful, Teamscale must not report additional findings, the peer-review must be passed, no tests fail. All of this is coordinated using merge requests.
Then we decided on fixed release dates, currently every six weeks. Due to the dense release frequency, it is no more a big problem if a feature moves to the subsequent release. Furthermore, we can deliver early prototypes of features easily by building a feature branch (with a merged master). This can be used in customers’ environments to gain feedback before we release such features. Thus, we gain a lot more stable prototypes and much happier users.
We are often asked if the high number of merges is a problem for us. Although I was a bit skeptical before we introduced our new process, we do not regard merge-efforts as very high, because Git does a good job and we usually do not have many concurrent overlapping changes. In any case, our team is convinced that the benefits we gain are much bigger than additional efforts.
Altogether, for us it was a big achievement to make this transition in our development methodology. If customers complain that they need to update their Teamscale more often due to the frequent releases, I take this as a compliment.
Impact on our CI: Faster builds and Teamscale with Branch Support
In order to get our new development process working efficiently, we did not only need to replace our Subversion with Git. Furthermore, we also needed to get a more flexible build infrastructure that is able to build every feature branch quickly. As we need build and test results for every feature branch the load on our build infrastructure increased very much. Thus, we did performance optimizations of our build scripts as well as our test execution and invested in new hardware.
However, not only build and test results are an entry criterion for starting manual reviews. Additionally, our developers need to proof that no static analyses findings were introduced due to their modifications. Of course we do not perform these analyses in the build but use Teamscale directly on every commit. In order to get immediate feedback, it is crucial to not only analyze the master branch but also every individual feature branch. In the following screenshot, you see the activity on our master branch with the visualization of the merges from/to feature branches.
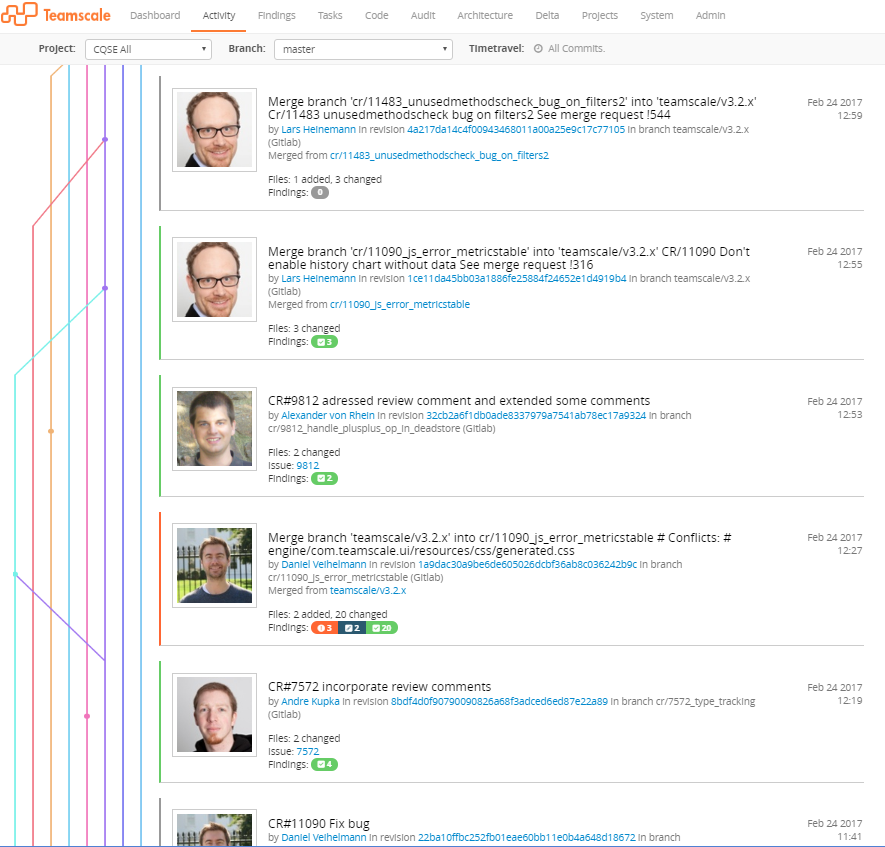
Teamscale’s branch support enables us to exactly know where the findings really come from. When analyzing only a master branch we would only see the (often big) merge commits and would not be able to see which changes really caused quality erosion. Even worse, the feedback would come much too late, when the problem already reached the master.
We have customers using Teamscale on more than 40 branches. With pre-3.0 versions of Teamscale they had to maintain 40 independent projects because Teamscale did not have a concept for branches. Furthermore, Teamscale had to analyze 40 times almost the same codebase (including their histories). As the 40 project configurations were (of course) highly redundant, changes always beard risks for inconsistencies. If a developer puts a finding to a blacklist, with every merge of these changes, the finding had to be blacklisted again in the corresponding project. Using branch support, only one project needs to be configured and maintained and thus, the resources (CPU, analysis time and memory) decreased additionally - less work for men and machine.
Altogether we are very happy with our new development infrastructure. Although Teamscale’s branch support was the most difficult, cross-cutting and painful feature we ever implemented, it not only resulted in great new functionality for our customers but also forced us to improve our own development process and tools.
