-
 Blog
Blog
-
Coding ABAP Like Java

In this blog-post I’d like to give a few insights on how we do ABAP programming at CQSE, which might be quite different than in most other ABAP development teams.
Normally, our programming language of choice at CQSE is Java for the most things—Teamscale’s backend as well as ConQAT are written in Java. But there is one component of Teamscale that is written in ABAP: This is the connector to an SAP ABAP system. The connector provides the functionality for the incremental retrieval of changed source code and also extracts further analysis data, e.g. test coverage, or results of the SAP Code Inspector, the common static analysis tool for ABAP, or some meta-data like the transport request numbers and descriptions.
When we started our own ABAP development, none of us was a pure ABAP programmer. At that time we wanted to code ABAP in a similar style as we did (and still do) in Java. Since the object-oriented concepts in both languages are quite similar, our assumption was that this should be possible in general. Now, about five years later, our experience is that this actually works very well. Of course, there are few rules to follow. Hence, over the years coding guidelines evolved from our development practice. This blog post describes the rules that we follow quite consequently now:
Use ABAP Development Tools for Eclipse (ADT)
Is there an alternative to ADT? Nobody would use Notepad to write Java… Seriously: refactoring capabilities (rename method!) as well as ABAP Doc comments are essential features for us. Thus SE80 is not an option.
Put Everything in Classes and Methods
Do not place functional code in programs (reports) or function groups/modules. As we come from Java, this is quite obvious. We use reports and function modules only if there is no other solution possible, e.g. for providing an RFC interface. And also in the rare cases where we had to leave the OO-world, these classical ABAP only serve as a proxy delegating to the actual implementation in a class.
Structure the Source Code by OO Concepts only
Especially, do not use includes. In our own codebase, there was only one exception: When we migrated our code from Z to /CQSE/ namespace, we wanted to keep the old Z programs as legacy interface for a while. Thus the Z programs just included the new /CQSE/ programs, we preferd this approach over code duplication.
Rules for Naming and Usage of Identifiers
In ABAP, it is common to use type prefixes in identifier names (Hungarian notation), e.g. lr_foo for a local variable of a reference type. This is completely unusual in Java and really hard to read if you’re not used to.
But the major problem is that it is difficult to keep the prefixes consistent, as in details the correct prefix is not always obvious: Consider for example the following questions: Should a local variable referencing to an object be named lr_foo or lo_foo? Does ls_bar point to a string or a structure? Does iv_input mean that the input parameter is of a (primitive) value type or that it is passed by value? Since this is confusing, our conventions are:
- No prefixes for variables. We don’t prefix variables, neither local nor member variables.
- Always use
me->orsome_class=>when accessing member variables. We use this to make the variable scope clear, even without prefixes. In Java we don’t do this, but for Java the IDE (Eclipse) formats the identifiers in different fonts depending on the scope. - Use prefixes for method parameters. ABAP knows—in contrast to Java—importing, exporting, changing and returning method parameter. Initially, we also used the parameters without any prefix, but this turned out to be not practical: as the method interface is defined separately from the method implementation, you typically don’t have the methods signature on your screen when reading a method’s implementation. Thus the prefixes
i_,e_,c_, orr_really help to instantly see, what a parameter is and if it is an importing, exporting, changing, or returning parametr. This is especially valuable for exporting and returning parameters to quickly locate what the method returns, thus instead for return you have to watch out forr_...to locate the return value.
Keep Method Calls Simple and Consistent
We strongly prefer to have methods with just input parameters and a returning parameter. We are using EXPORTING or CHANGE parameters with care. This helps to have a consistent and compact syntax for method calls like
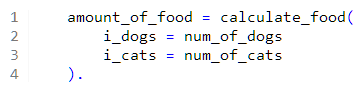
instead of

We also avoid superfluous keywords such as in the above example EXPORTING or CALL METHOD (for static calls, the latter is obsolete syntax anyway).
Do not use CALL FUNCTION
… at least not in regular coding. As our own code is all in classes and methods we don’t have any own function module to call. But we also do not use CALL FUNCTION for SAP standard functionality as well—at least not in our regular coding. Of course, we also have to use SAP standard functionality which is actually implemented in a function module. But, instead of calling a function module directly, we wrap it in a class method of specific utility classes. For example, we wrap the call to function module GET_SYSTEM_TIMEZONE like
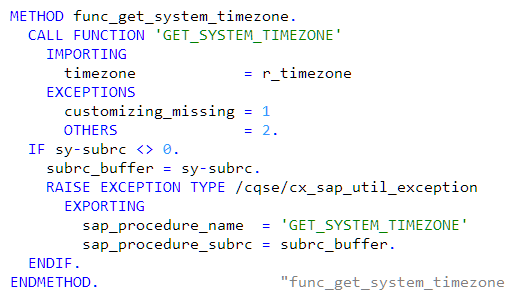
This has two advantages: First, in the regular coding we only have one consistent concept of modularization and a consistent way of calling procedures (see my point before). Here the call would be just time_zone = /cqse/cl_sap_util=>func_get_system_timezone( ).
Second, and more important, we only have to deal with class-based exception handling. The classical exceptions are also transformed in class-based exceptions, thus our wrapper methods throw /CQSE/CX_SAP_UTIL_EXCEPTION only. Sticking to a single concept of exception handling makes life much easier.
Do not call SAP Standard Code Directly
As said before, we wrap all function calls in specific proxy methods for it. Actually, this counts for any SAP standard functions we use, even if these are implemented in a method. Unfortunately, only very few of SAP’s API is formally released for public usage. For all the rest it is the developer’s risk to use it, since SAP may change it with any upgrade or patch level. The wrapper methods at least minimize this risk, as the fix to a changed behavior or API must be done in one place only. Luckily we’ve Teamscale’s architecture analysis available to easily identify calls to standard objects and make sure that these calls only occur in our /CQSE/CL_SAP_UTIL class.
Use ABAPDoc Consequently
Use ABAPDoc at all classes, interfaces and methods and type definitions. The same we did always with JavaDoc.
Don’t Copy
Of course, we follow the “don’t repeat yourself principle” consequently and strictly avoid duplicated code (code clones) within our code. Our current clone coverage (amount of duplicated code) is 0.6% - with just a single clone pair.
Finally: Keep Methods Short!
For Java, we try to keep our methods at a maximum of 30 SLOC (code lines without comment and blank lines). Even if we were aware the ABAP syntax is much more verbose then Java syntax, we aimed the 30 SLOC limit also for ABAP in the beginning. But meanwhile we have to admit that 30 SLOC is not really practical for ABAP, as it would lead to too many artificial method splits. Thus we changed the limit to 40 SLOC. And this works very well. We tolerate a few longer methods, but 89% of our code is within this 40 SLOC limit, our longest method has 61 SLOC. Strictly using the compact form of method call syntax and wrapping the lengthy function calls in methods makes this not as difficult. For further reasons behind this guideline on ABAP method length see my earlier post.
Summary
With all these guidelines, programming ABAP does actually not feel that different any more than programming Java. Still there are a few concepts where we follow traditional ABAP coding standards, e.g. we place all declarations at the beginning of a method and do not use inline declarations. We’d really love to use the latter, but we also must ensure that our code of the Teamscale Adapter runs on systems with ABAP < 7.40 as well. To summarize, it’s just a few rules one have to follow for a more modern ABAP programming style:
- No superfluous prefixes
- Only use the object oriented programming paradigm
- Wrap function calls to unify exception handling
- Use ABAPDoc everywhere
- Modularize, don’t copy&paste!
- Keep methods short!
As described before, we follow these guidelines quite consequently. Of course, there are exceptions, but these are rare and these are only accepted if there is a clear justification, as for example that a RFC function requires to implement a non-OO function module.
For the future, we also plan to modernize our development process, we would like to have feature branches as we have in our Java development using a Git repository. It looks very promissing to achieve this with abapGit and the set-up described by Ethan Jewett in his article Implementing modern practices in an ABAP development shop. For now, we use abapGit at least for having a real version history of our code.
Feel free to send us feedback on this article, I’d be very interested on your opinion about our ABAP coding guidelines.
