-
 Blog
Blog
-
Challenges of Architecture Documentation

I have always been a fan of architecture diagrams: I simply like the elaborate drawings that show how the complex whole is divided into parts and how those parts are connected. These blueprints are an essential foundation for any discussions and it is expected that they match the reality as closely as possible.
»Big design up front« has proven to be impractical in the software domain. For any non-trivial project, the domain complexity is usually so high that completing the design before starting the implementation is simply inefficient. As a counter-movement, some proponents of »agile« software development go as far as proposing no upfront design and no documentation at all. I find both approaches alarming and impractical. In this blog post, I will try and outline a light-weight documentation approach that focuses on the static perspective of software architecture, also known as »building block view«. I will also shed light on the frequently encountered architecture documentation challenges.
Missing Information
Apart from our tool Teamscale, CQSE also offers software audits. The reality that we are often faced with is either no architecture documentation at all or some drawings with simple boxes and strange coloring without connections between them. This does not quite match the architecture definition provided by IEEE 42010: »Fundamental concepts or properties of a system in its environment embodied in its elements, relationships, and in the principles of its design and evolution.« One of the most fundamental views is the »building block view« which shows the system’s static decomposition and the existing dependencies. As the arc42 template states, »This view is mandatory for every architecture documentation.«
These static properties are the foundation for any dynamic system behaviour, because if two components are forbidden to interact, then they cannot directly exchange any information.
As stated above, many architecture diagrams lack this basic information.
Inconsistent Decomposition
The architecture diagram of any sufficiently complex system can easily get complex itself with lots of components and dependencies. That’s why documentation guidelines like arc42 propose to design the static architecture on several levels. Unfortunately, the different abstraction levels need to be kept in sync otherwise the benefits decrease significantly. If for example one block is called »service«, but this label is neither found on the next abstraction level down nor in any module or namespace, then anybody looking at the code will wonder where the functionality belongs conceptually.
Using different terms for the same concept or using different concepts on different abstraction levels makes a system unnecessarily hard to understand.
Outdated Information
The third problem is that most architecture documentation is outdated before the ink has dried. Development teams need to move fast to fulfill the promise of agile development. This includes quick reactions to changing user requirements, as well as changes regarding third party libraries. Updating all architecture diagrams and keeping track of where the implementation needs to be updated is a task that is often neglected as it does not provide any short-term benefit to the project. While this focus on business outcome is very understandable, it adds a severe cognitive burden on all members of the team who are less experienced within the project history and heavily rely on the documentation.
If the implementation has to be checked every time to verify that the documentation is still correct, then the benefits of the abstraction level are practically lost.
Solution
The problems described above can be solved by modeling the static architecture within Teamscale. The following screenshot shows an extract of a detailed example architecture. Please note that Teamscale allows modeling the architecture within several diagrams, thus it is not required to force all information into one architecture definition.
Teamscale allows the definition of components as well as their dependencies. For me it makes the most sense to model dependencies based on provider and consumer of functionality as this is also the direction of the dependencies in the code base.
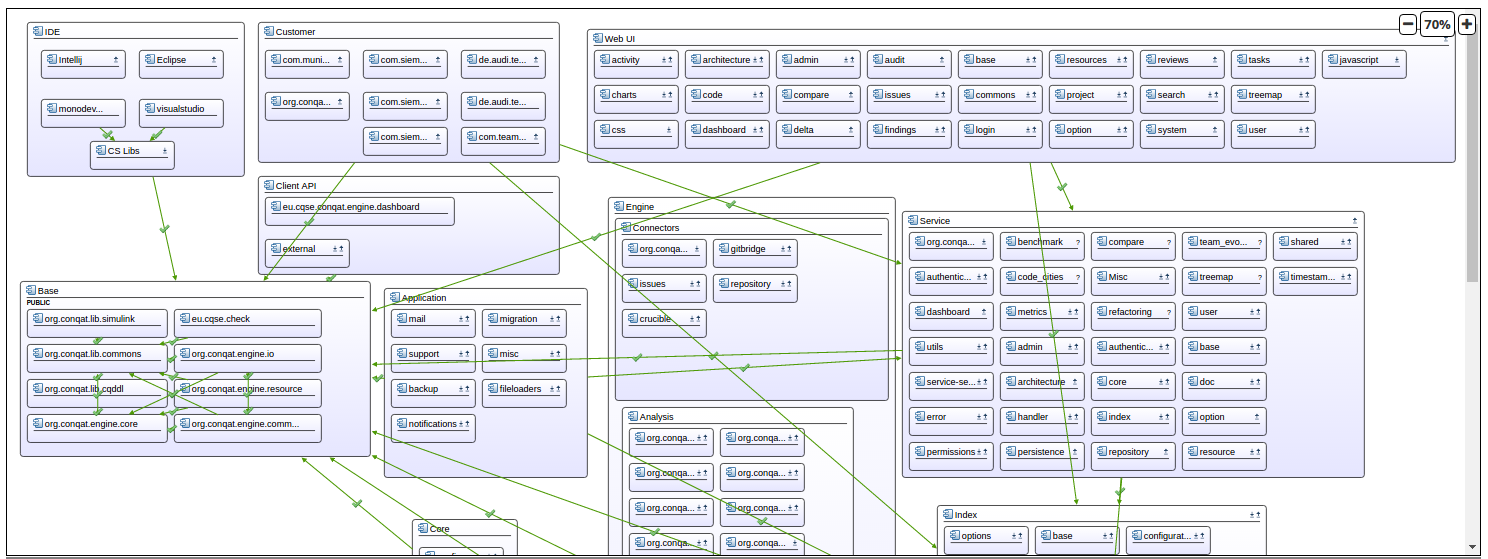
As for the second challenge of inconsistent decomposition, it can be tackled by nesting components. Mapping definitions assign code to components via regular expression patterns and Teamscale can check the conformance of the implementation automatically. For example, the pattern ‘./com/teamscale/ui/.’ matches all UI related files. More information about the architecture modeling in Teamscale can be found in Teamscale’s userguide and a related blog post.
Doing these conformance checks manually would be time consuming, error prone and the feedback usually comes days and weeks later, when the developer has long switched to another task. Additionally, the number of patterns needed for code assignment is a good indicator of whether the abstract concepts are used consistently within the code base. If a lot of patterns are needed, it usually means that the code base is not well structured and not following the separation of concerns principle.
Finally, Teamscale allows modeling and checking the architecture online. This means that the architect gets instant feedback about the compliance of the implementation during the design and modification of the architecture. If configured accordingly, Teamscale executes the same conformance checks for all changes made to the code base as part of the CI pipeline. Thus, updating the architecture is no longer a tedious documentation task that is easily forgotten, but rather an integral part of the development.
Summary
In this blog post I described problems concerning the modeling and implementation of software architecture that negatively affect the understanding of a system for anybody working in a big software project. Teamscale as a tool can help to solve these challenges by allowing the decomposition of the system in its components and also modeling the dependencies between them. As an additional benefit, Teamscale checks the conformance of the code to the architecture automatically and flags any violations or code that is not yet mapped to a component as findings. After all, letting a tool do this repetitive job frees your mind to concentrate on creative tasks.
